Spørsmål og svar
Data
Datatjenester
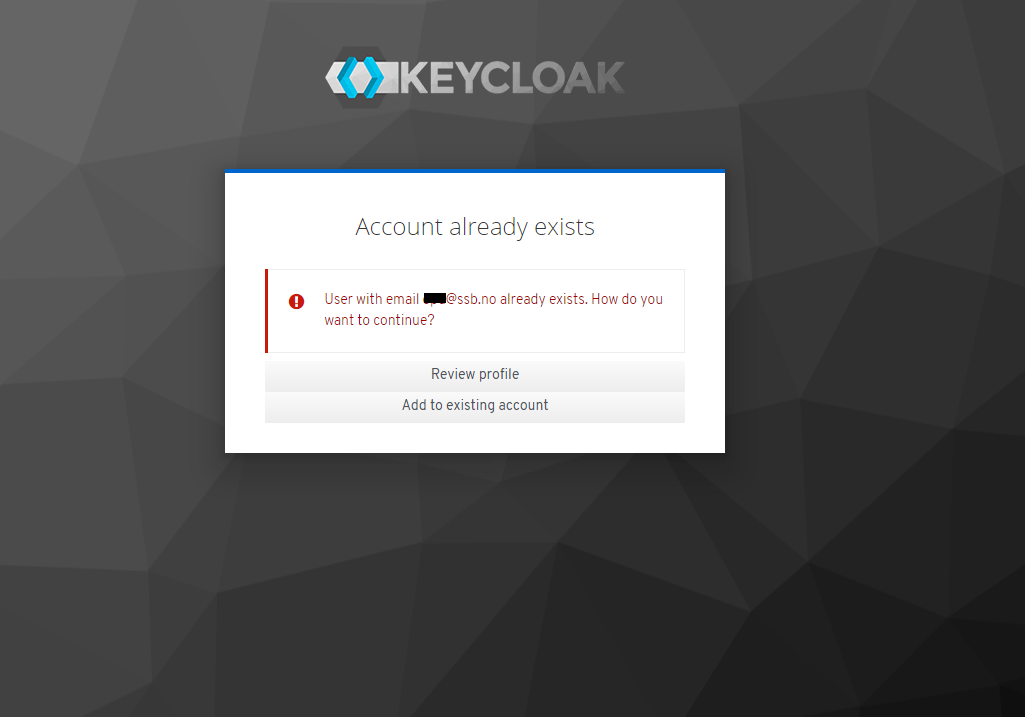
Det hender at man får melding om at Account already exists når man logger seg inn på en Dapla-tjeneste. For å løse dette gjør man følgende:
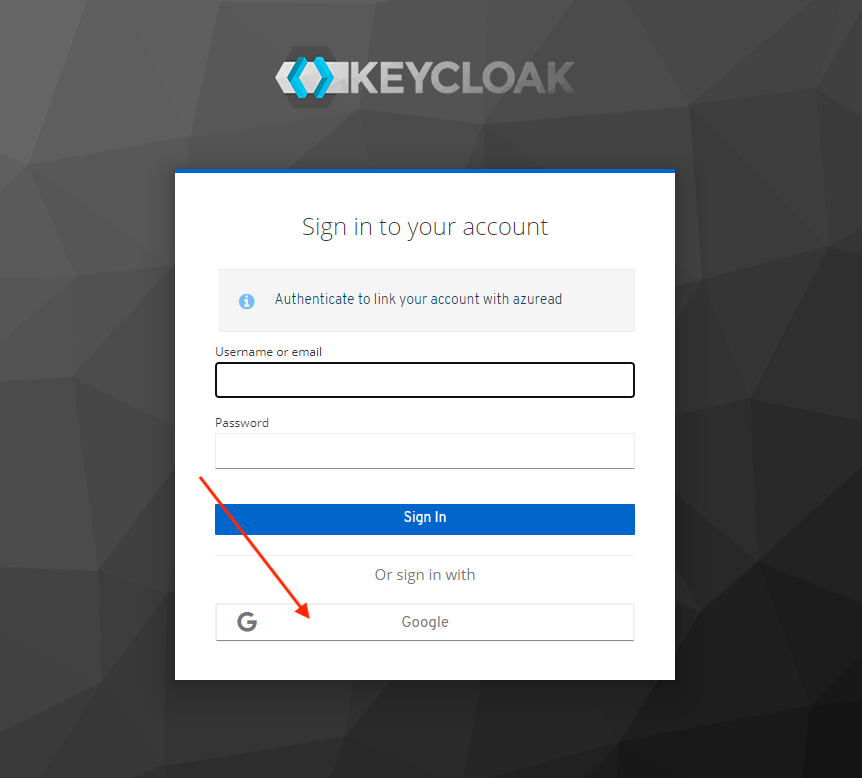
I Figur 2 skal du IKKE fylle inn Username or email og Password. Du skal kun trykke på Google-knappen.
Meldingen om at Account already exists forekommer svært sjelden, og typisk skjer det første gang man logger seg inn på en tjeneste.
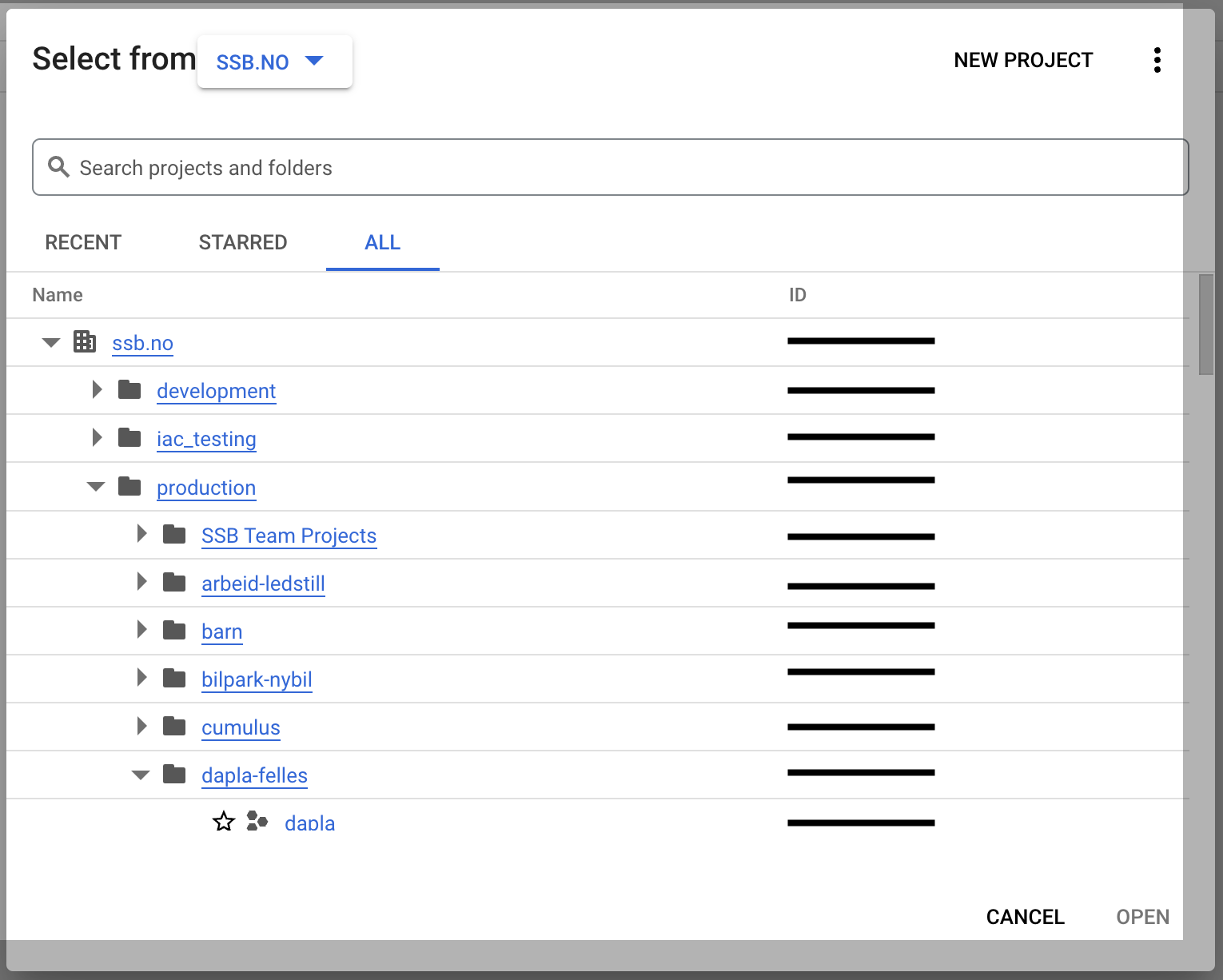
Prosjekt-ID-en til et Google-prosjekt er en unik identifikator som brukes til å identifisere prosjektet i Google Cloud Platform. Prosjekt-ID-en er en streng som består av små bokstaver, tall og bindestrek. Prosjekt-ID-en er ikke det samme som prosjektnavnet, som kan inneholde store bokstaver og mellomrom.
Du finner prosjekt-ID ved logge deg inn på GCC, åpne prosjektvelgeren, søk opp ditt prosjekt, og så ser du det i høyre kolonne, slik som vist i denne sladdete kolonnen i Figur 3.
Hvis man får feilmeldinger ved utrulling av Delomat-jobber, så bør man først undersøke hva feilmeldingen sier. Den gir ofte nyttige tilbakemelding om det er gjort noen formelle feil. Hvis dette ikke fører frem, så kan man ta kontakt med Kundeservice for hjelp.
Konfigurasjonsfilen valideres automatisk når du oppretter en pull request i GitHub. Hvis noe er feil får du en feilmelding: 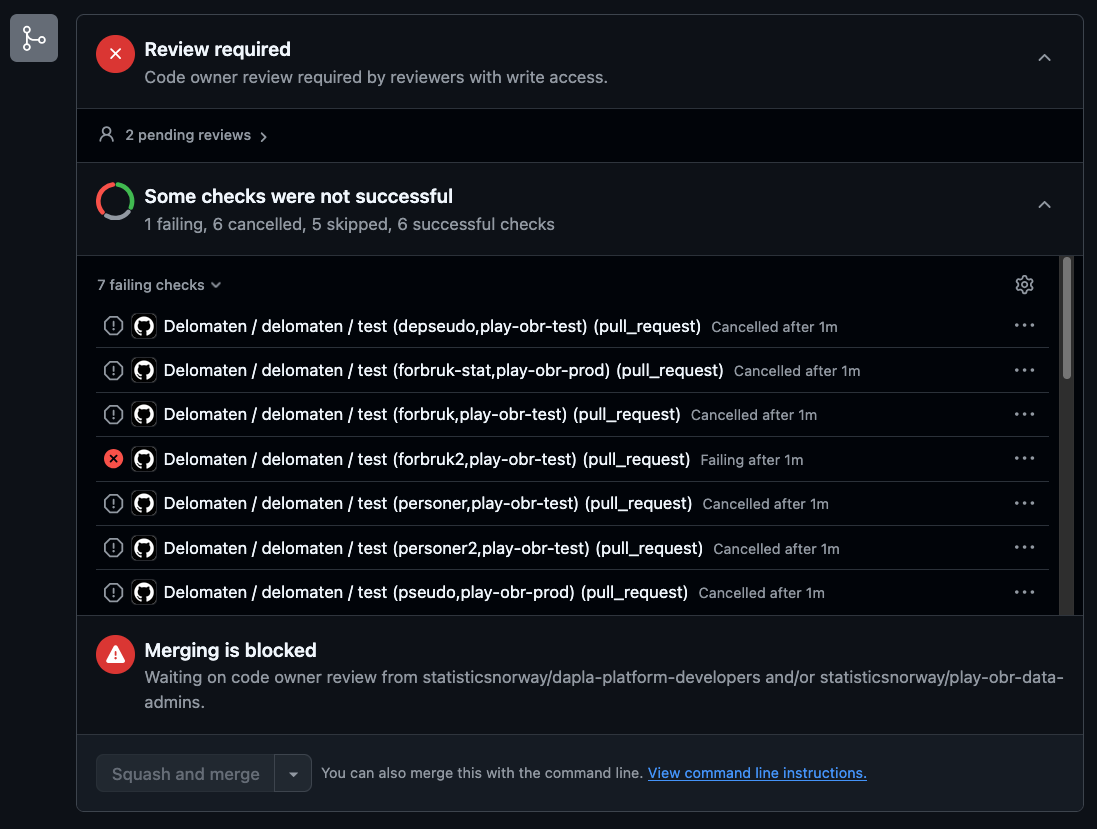
Eksempel på feilmelding i workflow 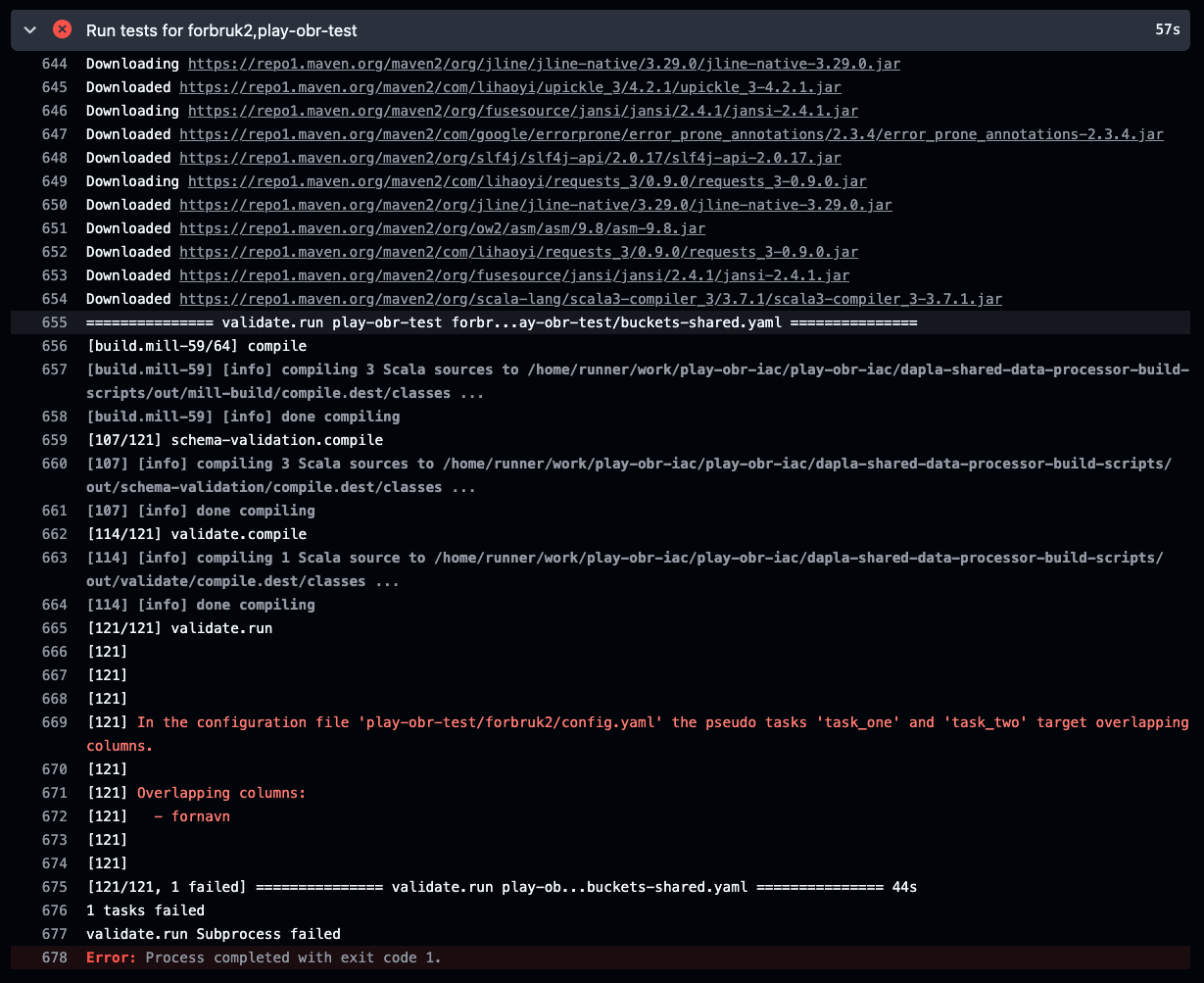
Man kan pause en regelmessig jobb med Transfer Service fra Google Cloud Console i nettleseren.

- Søk opp Transfer Jobs i søkefeltet øverst på siden.
- Velg hvilken Transfer Service jobb som skal endres.
- Velg Disable job som vist i Figur 5
For å aktivere jobben kan man følge stegene over, men da velge Enable job i siste steg.
Dapla Lab
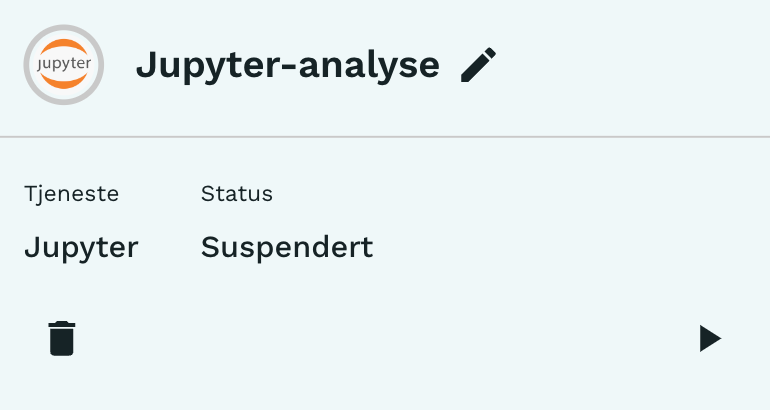
At en tjeneste er suspendert betyr at tjenesten er satt på pause. I praksis vil det si at ressursene, f.eks. CPU og RAM, som tjenesten har reservert har blitt frigjort. Man kan starte tjenesten på nytt ved å trykke på Play-knappen i bildet til høyre, og man starter opp tjenesten på nytt med de samme ressursene. Alt som ble lagret i tjenestens lokale filsystem under /home/onyxia/work/blir også gjennopprettet, mens resten blir borte. Derfor bør alltid kode lagres under work-mappen.
Hvis du trenger å hente data fra eksterne kilder til bruk i statistikkproduksjonen (f.eks. APIer), må du søke om tilgang til dette hos Team M2M. Dette gjøres ved å melde sak til Kundeservice. Se veiledning nedenfor.
Fra Byrånettet velg Arbeidsverktøy og Meld sak til kundeservice. Logg deg inn ved å velge Logg inn med federert autentisering. Inne løsningen velger du deretter Dapla helpdesk. Figur 6 viser menyen som vises.
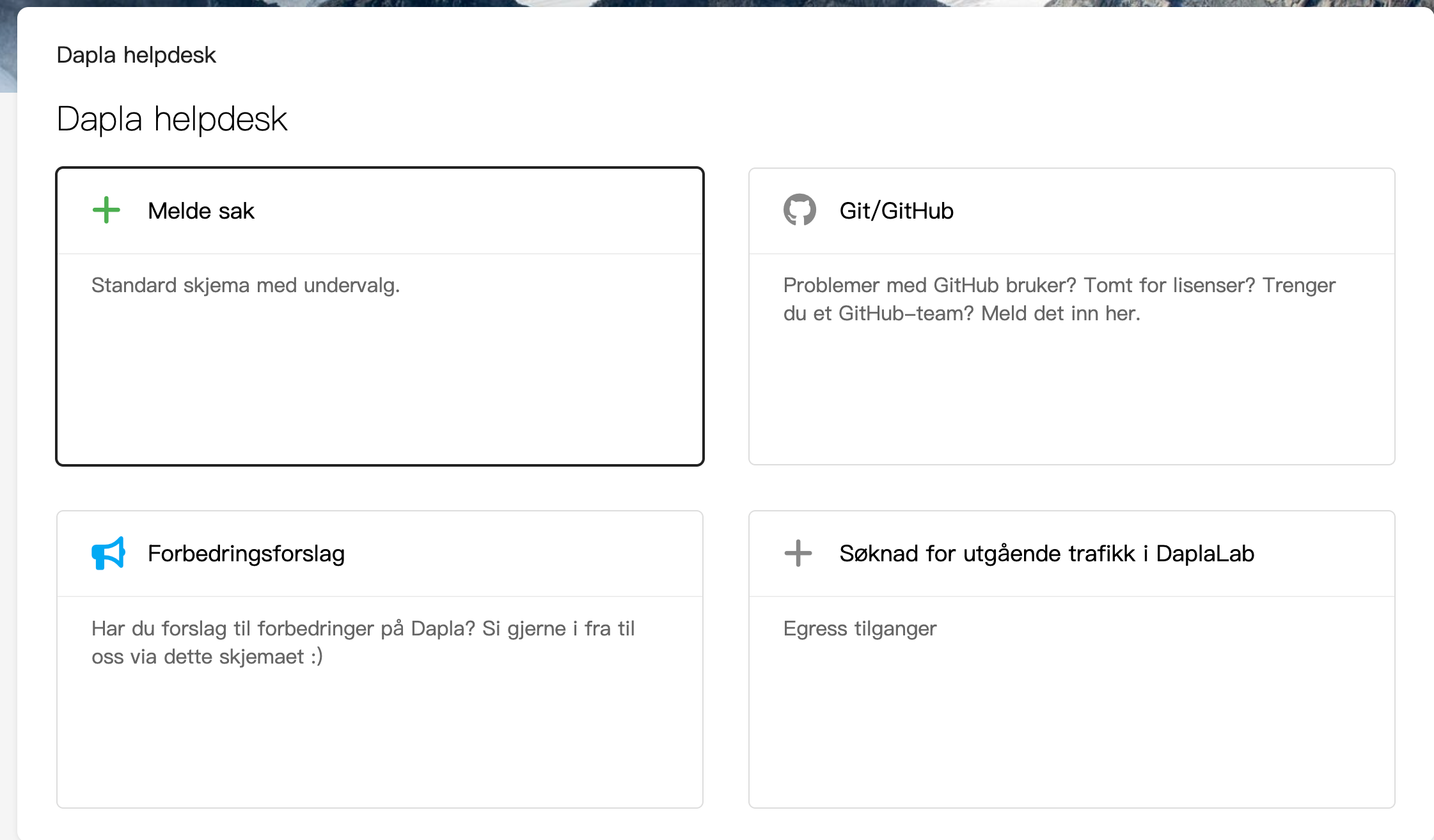
Fra menyen velger du Søknad for utgående trafikk i DaplaLab, fyller ut skjemaet som vises og trykker på «Send».
Team M2M vil så godkjenne eller avslå søknaden. Hvis søknaden godkjennes sendes saken videre til Kundeservice for effektuering. Hvis avslag så får du en begrunnelse for dette fra Team M2M.