Jupyter
Jupyter er en tjeneste på Dapla Lab som lar brukerne kode i Jupyterlab. Tjenesten kommer med R og Python og noen vanlige Jupyterlab-extensions ferdig installert. Målgruppen for tjenesten er brukere som skal skrive produksjonskode i Jupyterlab.
Siden tjenesten er ment for produksjonskode så er det veldig få R- og Python-pakker som er forhåndsinstallert. Antagelsen er at brukeren/teamet heller bør installere de pakkene de selv trenger, framfor at det ligger ferdiginstallerte pakker som skal dekke behovet til alle brukere/team i SSB. Det reduserer kompleksitet i tjenesten og dermed sannsynligheten for feilsituasjoner.
For uerfarne brukere finnes det en egen tjeneste som heter Jupyter-playground. Her er mange av de vanlige R- og Python-pakkene installert og det er opprettet en ferdig kernel som lar brukerne komme i gang fort med koding. Denne tjenesten er ikke tenkt for bruk i produksjonskode.
Forberedelser
Før man starter Jupyter-tjenesten bør man ha lest kapitlet om Dapla Lab og satt opp Git- og GitHub-konfigurasjonen under Min konto. Deretter gjør du følgende:
- Logg deg inn på Dapla Lab
- Under Tjenestekatalog trykker du på Start-knappen for Jupyter
- Gi tjenesten et navn
- Åpne Jupyter konfigurasjoner
Konfigurasjon
Før man åpner en tjeneste kan man konfigurere hvor mye ressurser man ønsker, hvilket team man skal representere, om et GitHub-repo skal klones ved oppstart, og mange andre ting. Valgene man gjør kan også lagres slik at man å slipper å gjøre samme jobb senere. Figur 1 viser Tjeneste-delen i konfigurasjonen for Jupyter hvor man kan velge hvilken versjon av Jupyter man vil bruke.

Data
Under Data-menyen kan man velge hvilket team og tilgangsgruppe man skal representere, som igjen bestemmer hvilke data man får tilgang til. Man gjør dette ved å velge navnet på tilgangsgruppen, og denne er alltid på formen <teamnavn>-<tilgangsgruppe>. Figur 2 viser at brukeren har valgt tilgangsgruppen dapla-felles-developers, dvs. at de representerer tilgangsgruppen developers for teamet dapla-felles.
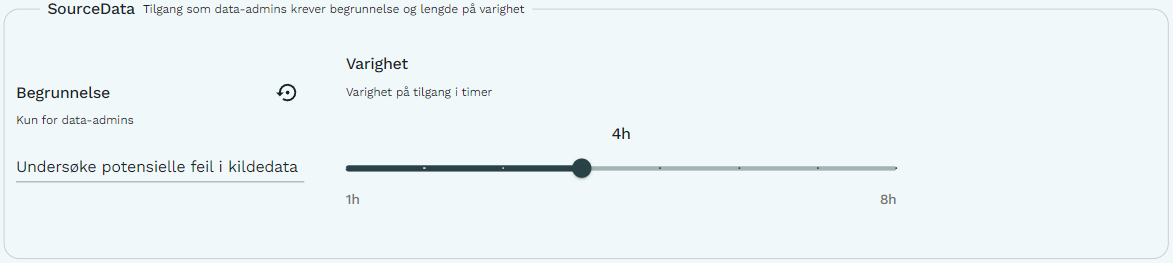
Under Team og tilgangsgruppe kan brukeren også velge å representere tilgangsgruppen data-admins for et team. I de tilfellene er det et krav om brukeren oppgir en skriftlig begrunnelse for hvorfor tilgangen er nødvendig. I tillegg må kan de maksimalt aktivere tilgangen i 8 timer.
Figur 3 viser en bruker som aktiverer sin data-admins tilgang for team dapla-felles. Hvis brukeren ikke oppgir en begrunnelse vil de få en feilmelding ved oppstart av tjenesten.
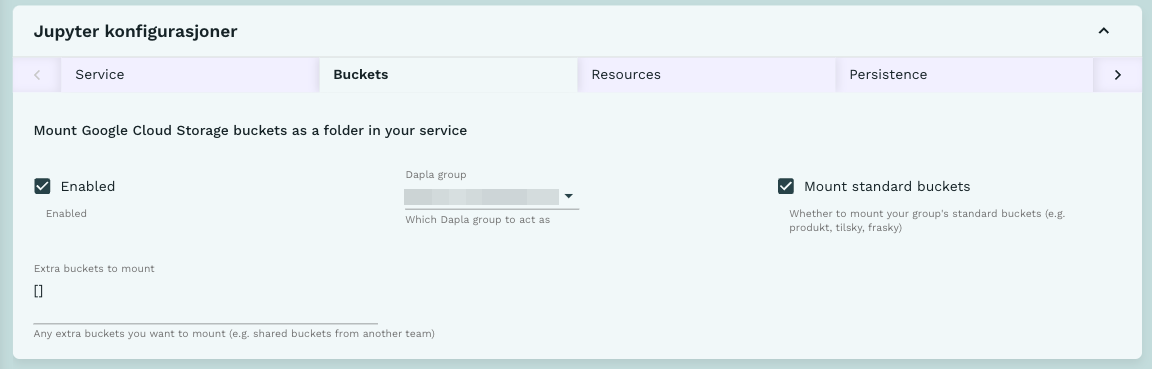
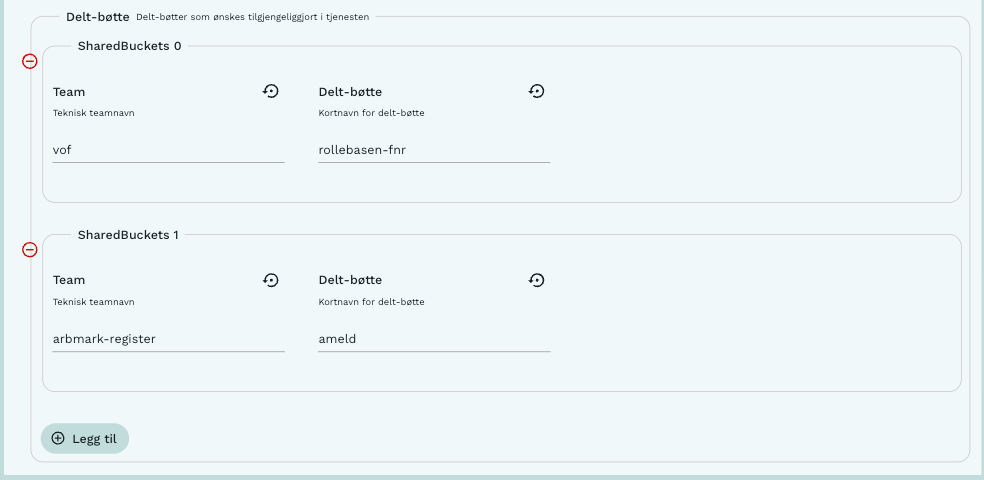
Når man åpner tjeneste, og representerer et team, så tilgjengeliggjøres det teamets bøtter inne i tjenesten under filstien /buckets/. Men et team kan også ha tilgang til andre sine delt-bøtter og ønske å tilgjengliggjøre disse også. Figur 4 viser hvordan man spesifiserer hvilke delt-bøtter man ønsker å tilgjengeliggjøre inne i tjenesten. Man gjør det ved å spesifisere det tekniske teamnavnet til teamet som eier dataene, og spesifiserer kortnavnet for delt-bøtta1.
Bøtter som tilgjengeliggjøres inne tjenesten finner du alltid under filstien /buckets/ i tjenesten. Under er et eksempel som vil være vanlig for et statistikkteam:
Filsystem
/buckets/
├── produkt/
│ ├── inndata/
│ └── klargjorte data/
├── frasky/
├── tilsky/
├── delt-ledstill/
├── delt-freg/
└── shared/
├── arbmark-register/
│ └── ameld/
└── vof/
└── rollebasen/Bøttene som eies av teamet (produkt, frasky, tilsky, delt-ledstill og delt-freg) tilgjengeliggjøres rett under filstien /buckets/, mens andre team sine delt-bøtter tilgjengeliggjøres under /buckets/shared/<teamnavn>/<kortnavn for bøtte>. Teamets egne delt-bøtter får et delt-prefiks slik at en delt-bøtte med kortnavn ledstill blir tilgjengeliggjort som delt-ledstill.
Man kan også velge å jobbe direkte mot bøttene, og da trenger man ikke å tilgjengeliggjøre bøttene i filsystemet. Under tjenestekonfigurasjonen Avansert kan man skru av tilgjengeliggjøringen av bøtter i filsystemet.
Git/GitHub
Under menyen Git/GitHub kan man konfigurere Git og GitHub slik at det blir lettere å jobbe med inne i tjenesten. Som standard arves informasjonen som er lagret under Min konto-Git i Dapla Lab. Informasjonen under tjenestekonfigurasjonen blir tilgjengeliggjort som miljøvariabler i tjenesten. Informasjonen blir også lagt i $HOME/.netrc slik at man kan benytte ikke trenger å gjøre noe mer for å jobbe mot GitHub fra tjenesten.
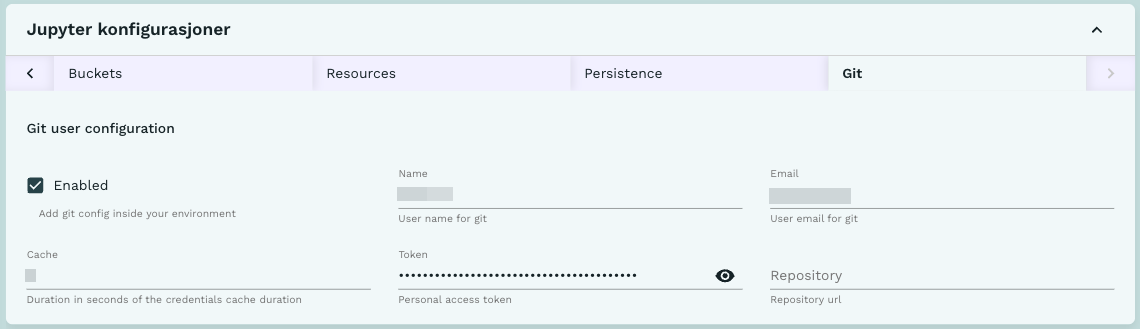
Figur 5 viser at brukeren som standard får aktivert Aktiver Git. Dette innebærer at Git-brukernavn, Git e-post og GitHub-token arves fra brukerkonfigurasjonen. I tillegg så opprettes SSBs standard Git-konfigurasjon i ~/.gitconfig.
Man kan også velge at ssb-project build skal kjøres på repoet under oppstart av tjenesten. Det fører til litt lengre oppstartstid, men er alle pakker installert og en kernel opprettet når tjenesten er klar.
Klone repo ved oppstart
Legger man inn lenke til repo under Repo i tjenestekonfigurasjonen vil repoet klones ved oppstart. Hvis jeg for eksempel vil klone repoet for Dapla-manualen ved oppstart skriver jeg https://github.com/statisticsnorway/dapla-manual.git i feltet.
Python/R
Under menyen Python/R kan man velge hvilke versjon av R og Python man ønsker å kjøre. Man kan velge mellom alle tidligere tilbudte kombinasjoner av R og Python.
I Figur 6 ser vi av navnet r4.4.0-py311-v55-2024.10.31 at tjenesten som default vil startes versjon 4.4.0 av R og 3.11 for Python. Etterhvert som nye versjoner av R og Python kommer kan disse tilgjengeliggjøres i tjenesten, men brukeren kan velge å starte en eldre versjon av tjenesten.

Ressurser
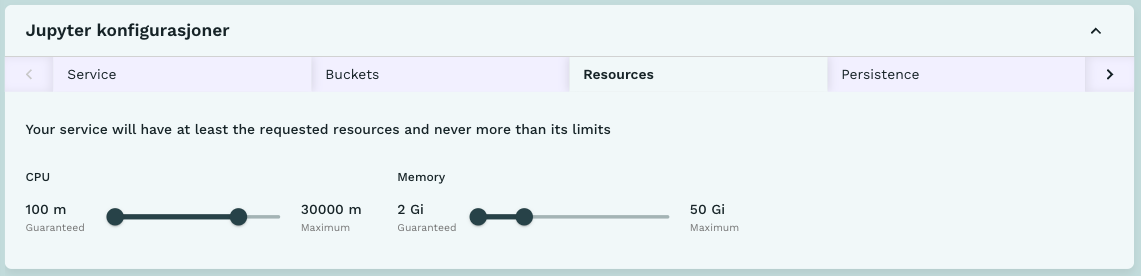
Under menyen Resources kan man velge hvor mye CPU og RAM man ønsker i tjenesten, slik som vist i Figur 7. Velg så lite som trengs for å gjøre jobben du skal gjøre.
Diskplass
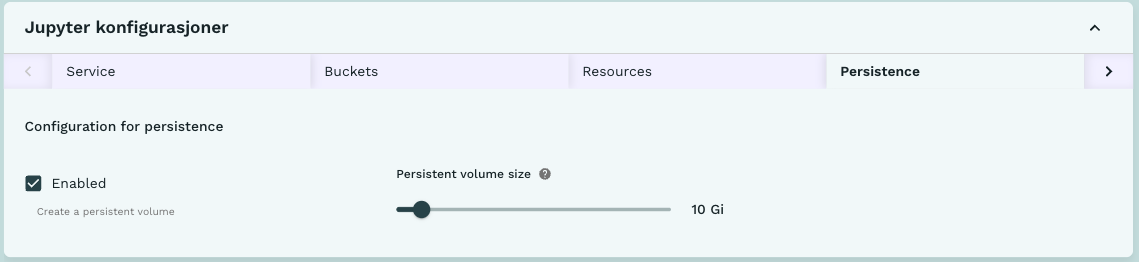
Som default får alle som starter en instans av Jupyter-tjenesten en lokal disk på 10GB inne i tjenesten. Under Diskplass-menyen kan man velge å øke størrelsen på disken eller ikke noe disk i det hele tatt. Siden lokal disk i tjenesten hovedsakelig skal benyttes til å lagre en lokal kopi av koden som lagres på GitHub mens man gjør endringer bør ikke størrelsen på disken være stor. Figur 8 viser valgene som kan gjøres under Diskplass-fanen.
Avansert
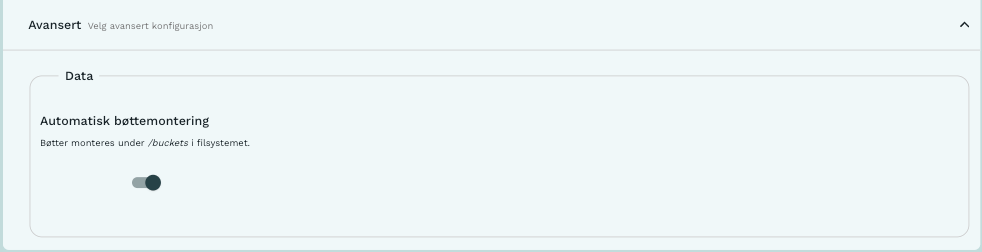
Under Data i Avansert kan man velge å ikke tilgjengeliggjøre bøtter som filsystem inne i tjenesten. Konsekvensen av dette er at man må lese og skrive filer ved å referere til bøttene direkte.
Under Oppstartsskript kan man velge angi et bash-script som skal kjøres ved oppstart av tjenesten. Skriptet må ligge lagret på www.github.com/statisticsnorway, og under Bash-skript-delen oppgis kun navn på repo og sti i repoet, f.eks. stat-ledstill/utilities/ledstill-startupscript.sh. Hvis skriptet tar argumenter kan man oppgi disse under Argumenter.
I oppstartsskriptet kan man gjøre alt som er mulig å gjøre i terminalen etter at tjenesten er startet. F.eks. kan man:
- definere miljøvariabler
- legge til ønsket konfigurasjon i
.bashrc - konfigurere farger og andre innstillinger i Jupyter, VS Code og RStudio
demo-script.sh
#!/bin/bash
# Update .bashrc with environment variables and aliases
echo "" >> "$HOME/.bashrc"
echo "# Opprettet av mitt personlige startupscript:" >> "$HOME/.bashrc"
echo "export TEST=true" >> "$HOME/.bashrc"
echo "alias gs='git status'" >> "$HOME/.bashrc"
echo "alias ll='ls -alF'" >> "$HOME/.bashrc"
# Set Jupyter-theme via settings file
THEME_NAME="JupyterLab Dark"
SETTINGS_DIR="$HOME/work/.jupyter/config/lab/user-settings/@jupyterlab/apputils-extension"
SETTINGS_FILE="$SETTINGS_DIR/themes.jupyterlab-settings"
mkdir -p "$SETTINGS_DIR"
cat > "$SETTINGS_FILE" <<EOF
{
// Theme set from init-script
"theme": "$THEME_NAME"
}
EOF
echo "[Init Script] JupyterLab theme set to '$THEME_NAME'"Hvis oppstartsskriptet feiler, eller man er interessert i hva som ble kjørt, så kan man undersøke logg-filen til oppstartskriptet inne i tjenesten: $HOME/personal_init_script.log.
Datatilgang
Slik kan man inspisere dataene fra en terminal inne i tjenesten:
- Åpne en instans av Jupyter med data fra bøtter
- Åpne en terminal inne i Jupyter
- Gå til mappen med bøttene ved å kjøre dette fra terminalen
cd /buckets - Kjør
ls -ahli teminalen for å se på hvilke bøtter som er montert.
Installere pakker
Siden det nesten ikke er installert noen pakker i tjenesten så kan brukeren opprette et ssb-project og installere pakker som vanlig.
For å bygge et eksisterende ssb-project så kan brukeren også bruke ssb-project.
For å installere R-pakker følger man beskrivelsen for renv.
Slette tjenesten
For å slette tjenesten kan man trykke på Slette-knappen i Dapla Lab under Mine tjenester. Når man sletter en tjeneste så sletter man hele disken inne i tjenesten og frigjør alle ressurser som er reservert. Vi anbefaler at man avslutter heller pauser tjenester som ikke benyttes.
Pause tjenesten
Man kan pause tjenesten ved å trykke på Pause-knappen i Dapla Lab under Mine tjenester. Når man pauser så slettes alt påden lokale disken som ikke er lagret under $HOME/work. Vi anbefaler at man avslutter heller pauser tjenester som ikke benyttes.
Monitorering
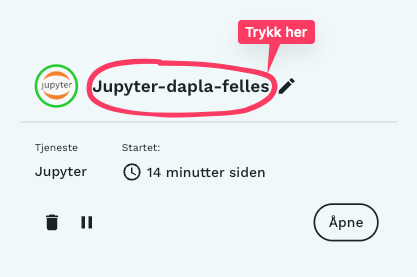
Man kan moniterere en instans av Jupyter ved å trykke på Jupyter-teksten under Mine tjenester i Dapla Lab, slik som vist i Figur 10.
Denne funksjonaliteten er under arbeid og mer informasjon kommer snart.
Fotnoter
Kortnavnet til en delt-bøtte kan leses ut av Dapla Ctrl eller hentes fra selve bøttenavnet. F.eks. er det kortnavnet til delt-bøtta
ssb-vof-data-delt-rollebase-fnr-prodbarerollebase-fnr. Det tekniske teamnavnet ervof.↩︎