Jupyter-pyspark
Jupyter-pyspark er en tjeneste på Dapla Lab som lar brukerne kode i Jupyterlab. Tjenesten kommer med Python, Pyspark og noen vanlige Jupyterlab-extensions ferdig installert. Målgruppen for tjenesten er brukere som skal skrive produksjonskode med Pyspark i Jupyterlab.
Siden tjenesten er ment for produksjonskode så er det veldig få Python-pakker som er forhåndsinstallert. Antagelsen er at brukeren/teamet heller bør installere de pakkene de selv trenger, framfor at det ligger ferdiginstallerte pakker som skal dekke behovet til alle brukere/team i SSB. Det reduserer kompleksitet i tjenesten og dermed sannsynligheten for feilsituasjoner.
Forberedelser
Før man starter Jupyter-pyspark bør man ha lest kapitlet om Dapla Lab og satt opp Git- og GitHub-konfigurasjonen under Min konto. Deretter gjør du følgende:
- Logg deg inn på Dapla Lab
- Under Tjenestekatalog trykker du på Start-knappen for Jupyter-pyspark
- Gi tjenesten et navn
- Åpne Jupyter-pyspark konfigurasjoner
Konfigurasjon
Konfigurasjonen av Jupyter-pyspark er nær identisk Jupyter-tjenesten sin konfigurasjon. Se dokumentasjonen for konfigurasjon av Jupyter.
Tilgjengelige JAR-filer og bruk i PySpark
I /jupyter/lib-mappen i Jupyter-pyspark-miljøet er flere nyttige JAR-filer tilgjengelige for bruk med PySpark, inkludert støtte for Google Cloud Storage, BigQuery, Avro og Delta Lake. Disse JAR-filene kan inkluderes i PySpark-konfigurasjonen for å få tilgang til og arbeide med data fra disse kildene.
- Tilgjengelige JAR-filer:
gcs-connector-hadoop.jar: Kobler PySpark til Google Cloud Storage.spark-bigquery-with-dependencies_2.12.jar: Kobler PySpark til Google BigQuery.spark-avro_2.12.jar: Støtte for å lese og skrive Avro-data.delta-storage.jarogdelta-core_2.12.jar: Støtte for Delta Lake, som muliggjør ACID-transaksjoner og data versjonering.
- Legge til JAR-filer i PySpark:
For å bruke disse JAR-filene, konfigurer PySpark med stien til hver fil:
spark = SparkSession.builder \ .appName("Jupyter-pyspark-konfig") \ .config("spark.jars", "/jupyter/lib/gcs-connector-hadoop.jar," "/jupyter/lib/spark-bigquery-with-dependencies_2.12.jar," "/jupyter/lib/spark-avro_2.12.jar," "/jupyter/lib/delta-storage.jar," "/jupyter/lib/delta-core_2.12.jar") \ .getOrCreate()
- Eksempler på bruk av tilkoblingene:
Google Cloud Storage (GCS):
df = spark.read.format("parquet").load("gs://ditt-bucket-navn/path/to/data")Google BigQuery:
df = spark.read.format("bigquery") \ .option("table", "prosjekt_id.dataset_id.tabell_id") \ .load()Avro:
df = spark.read.format("avro").load("/path/to/avro/files")Delta Lake:
For å skrive til en Delta-tabell:
df.write.format("delta").save("/path/to/delta-table")For å lese fra en Delta-tabell:
delta_df = spark.read.format("delta").load("/path/to/delta-table")
Med disse instruksjonene kan brukerne effektivt konfigurere Jupyter-PySpark til å jobbe med eksterne datakilder og forskjellige dataformater i sitt PySpark-miljø.
Hvordan Spark Lokalt Fungerer og Arbeidsfordeling på Kjerner
Når Spark kjøres lokalt, starter det en SparkSession som kjører på en enkelt node (tjenesten din) uten å involvere en distribuert klynge. Lokalt i Spark kan du kontrollere ressursbruken og fordele arbeidsmengden på tilgjengelige CPU-kjerner for å optimalisere ytelsen.
Kjøring i Lokal Modus
Når Spark konfigureres til å kjøre i lokal modus, spesifiseres dette med "local[N]", der N representerer antall kjerner som Spark skal bruke. For eksempel: - "local[*]": Bruk alle tilgjengelige kjerner på maskinen. - "local[2]": Bruk 2 kjerner, uavhengig av hvor mange som er tilgjengelige.
Eksempel på konfigurasjon:
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("Lokal Spark") \
.master("local[*]") \ # Bruker alle tilgjengelige kjerner
.getOrCreate()Datatilgang
Man inspisere dataene fra en terminal inne i tjenesten:
- Åpne en instans av Jupyter-pyspark med data fra bøtter
- Åpne en terminal inne i Jupyter
- Gå til mappen med bøttene ved å kjøre dette fra terminalen
cd /buckets - Kjør
ls -ahli terminalen for å se på hvilke bøtter som er montert.
Installere pakker
Siden det nesten ikke er installert noen pakker i tjenesten så kan brukeren opprette et ssb-project og installere pakker som vanlig.
For å bygge et eksisterende ssb-project kan brukeren også bruke ssb-project.
Slette tjenesten
For å slette tjenesten kan man trykke på Slette-knappen i Dapla Lab under Mine tjenester. Når man sletter en tjeneste så slettes hele disken inne i tjenesten, og alle ressurser frigjøres. Vi anbefaler at man avslutter heller enn pauser tjenester som ikke benyttes.
Pause tjenesten
Man kan pause tjenesten ved å trykke på Pause-knappen i Dapla Lab under Mine tjenester. Når man pauser, slettes alt på den lokale disken som ikke er lagret under $HOME/work. Vi anbefaler at man avslutter heller enn pauser tjenester som ikke benyttes.
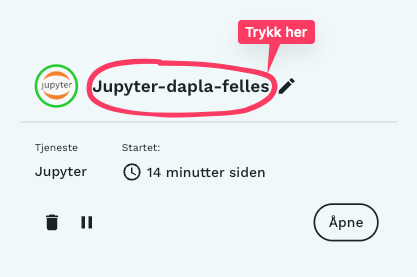
Monitorering
Man kan moniterere en instans av Jupyter-pyspark ved å trykke på Jupyter-pyspark-teksten under Mine tjenester i Dapla Lab, slik som vist i Figur 1.
Denne funksjonaliteten er under arbeid og mer informasjon kommer snart.