Delomaten
Delomaten er en tjeneste som lar Dapla-team dele data med hverandre selv om de behandler personopplysninger ulikt. Tjenesten håndterer spesialtilfeller der team ikke kan bruke standard delt-bøtter fordi teamet de skal dele med håndterer personopplysninger på en annen måte.
Delomaten lar team automatisere pseudonymisering eller de-pseudonymisering av informasjon før de deles. Selve prosesseringen skjer av en systembruker i Delomaten og brukerne får ikke direkte tilgang til å pseudonymisere eller de-pseudonymisere. Det delende teamet har ikke selv tilgang til dataene delt gjennom Delomaten, men andre team kan få tilgang.
Figur 1 viser et eksempel på hvordan tjenesten fungerer når et team som jobber med pseudonymiserte personopplysninger skal dele data et med et team som skal se personopplysninger i klartekst.

Av Figur 1 ser vi at team A jobber med pseudonymiserte personopplysninger i sin produktbøtte. Disse dataene kan de dele med andre team via standard delt-bøtter som team A kan skrive til. Hvis de i tillegg ønsker å dele data i klartekst (de-pseudonymisert) så må de dele via en Delomaten delt-bøtte. Team A kan da bruke Delomaten til å de-pseudonymisere dataene og skrive til Delomaten delt-bøtta uten at de selv har tilgang til den bøtta, mens team B har tilgang. Da håndterer Delomaten de-pseudonymisering og skriving til bøtta basert på konfigurasjon som team A setter opp.
Delomaten støtter også den motsatte flyten av det som er vist i Figur 1. Dvs. hvis et team som håndterer personopplysninger i klartekst i produktbøtta ønsker å dele med et team som kun skal se opplysningene pseudonymisert. Re-pseudonymisering, dvs. bytte av krypteringsalgoritme eller nøkkel, støttes ikke av Delomaten enda.
Hvem kan bruke Delomaten?
Før man tar i bruk Delomaten skal teamet diskutere formålet med delingen og tilgangsstyring med nærmeste leder. Delomaten er en tjeneste som skal benyttes unntaksvis og alle andre løsninger bør vurderes før man tar den i bruk. Det er også anbefalt at teamet rådfører seg meg Personvernombudet før man tar i bruk Delomaten.
Forberedelser
Under beskrives hvilke tekniske krav som gjelder for Delomaten.
Dokumentasjon
Data som skal deles gjennom Delomaten-bøtter må være dokumentert i Datadoc. Alle obligatoriske felt i Datadoc må være utfylt og metadata-filen (.json) må ligge lagret med riktig navn ved siden av data-filen. Delomaten-jobbene vil feile dersom den ikke finner metadatafilen.
For at Delomaten skal kunne de-pseudonymisere data så krever den at de tekniske detaljene om hvordan dataene er pseudonymisert er dokumentert i Datadoc for hver variabel som skal prosesseres. Den enkleste måten å legge inn metadata er gjøre det når dataene pseudonymiseres. Hvis man ikke har gjort dette, så kan man legge det inn ved hjelp av Datadoc-editor.
Aktiver Delomaten
Delomaten er en feature som må aktiveres for hvert team som skal bruke den. Du aktiverer den i teamets IaC-repo slik som vist på linje 14 i eksempelet under:
Opprett Delomaten-bøtte
Før man kan ta i bruk Delomaten må man opprette en Delomaten delt-bøtte. Les mer om hvordan man oppretter en slik bøtte i denne artikkelen.
Sett opp tjenesten
Under beskrives det hvordan man setter opp Delomaten.
Klone IaC-repoet
Oppsett av Delomaten gjøres i teamets IaC-repo1. Når vi skal sette opp Delomaten må vi gjøre endringer i teamets IaC-repo. Man finner teamets IaC-repo ved gå inn på SSBs GitHub-organisasjon og søke etter repoet som heter <teamnavn>-iac. Når du har funnet repoet så kan du gjøre følgende:
- Klon teamets IaC-repo
git clone <repo-url> - Opprett en ny branch:
git switch -c add-delomaten-source
Mappestruktur i IaC-repo
For at Delomaten skal fungere må det opprettes en bestemt mappestruktur i IaC-repoet til teamet. F.eks. vil mappestrukturen for prod-miljøet se slik ut for team dapla-example:
github.com/statisticsnorway/dapla-example-iac
dapla-example-iac
├── automation/
│ └── shared-data/
│ ├── dapla-example-prod/
│ └── README.md
│
│...Skal du sette opp Delomaten i prod-miljøet kan du følge oppskriften som kommer senere i kapitlet uten å gjøre noe mer enda.
Skal du også bruke Delomaten i test-miljøet må du opprette en ny mappe og lage en PR i IaC-repoet til teamet. Da vil strukturen se slik ut:
github.com/statisticsnorway/dapla-example-iac
dapla-example-iac
├── automation/
│ └── shared-data/
│ ├── dapla-example-prod/
│ │ └── README.md
│ ├── dapla-example-test/
│...I mappestrukturen over har vi klargjort den grunnleggende mappestrukturen for å ta i bruk kildomaten i prod- og test-miljøet. Neste steg blir å legge de ulike kildene som egne mapper under dapla-example-prod og dapla-example-test. Det viser vi i neste avsnitt.
Flere kilder
Delomaten lar deg prosessere ulike filstier ulikt. Dette refereres til som at Delomaten har flere jobber. For å sette opp en jobb må man følge en definert mappestruktur i IaC-repoet der alle jobbene ligger rett under <teamnavn>-prod- eller <teamnavn>-test-mappen. Du kan ikke ha undermapper under en jobb. Du velger selv navnet på jobbene/mappene i IaC-repoet, og det vil være navnet på jobbene i Delomaten. Senere i kapitlet ser vi at vi må bruke navnet for trigge re-kjøring av kilder.
Under er et eksempel på hvordan det kan se ut for eksempel-teamet dapla-example:
github.com/statisticsnorway/dapla-example-iac
dapla-example-iac
├── automation/
│ └── shared-data/
│ ├── dapla-example-prod/
│ │ └── altinn
│ │ └── ameld
│ ├── dapla-example-test/
│ │ └── altinn
│ │ └── ameld
│ │ └── nudb
│...I eksempelet over ser vi at det er mapper i IaC-repoet for jobbene altinn og ameld for både test- og prod-miljøet. I tillegg har test-miljøet en mappe for jobben nudb. Hver av disse kildene kan kjøre ulike jobber på alle filer som skrives til en gitt filsti som man definerer selv.
Et team kan sette opp forskjellige jobber for forskjellig data, men Delomaten tillater bare ett nivå under automation/source-data-<teamnavn>-<miljø>/. Det vil si at du ikke kan ha undermapper under en jobb. Det er også slik at man alltid må opprette en mappe for en jobb, selv om du kun har en jobb. F.eks. kan man ikke droppe mappen altinn i eksempelet over.
Konfigurasjonsfilen
Konfigurasjonsfilen (config.yaml) styrer hvordan Delomaten skal behandle dataene. Filen må ligge i under mappen for en jobb i teamets IaC-repo. I eksempelet under ser vi at det er configurert en jobb som heter altinn med en konfigurasjonsfil.
github.com/statisticsnorway/dapla-example-iac
dapla-example-iac
├── automation/
│ ├── shared-data/
│ │ ├── dapla-example-prod/
│ │ │ └── altinn
│ │ │ └── config.yaml
│ │ │ └── ameld
│ │ └── dapla-example-test/
│ │ └── altinn
│ │ └── ameld
│ │ └── skatt
│ └── source-data/
│ ...
│...I konfigurasjonsfilen kan teamet bestemme prosesseringen i Delomaten-jobben ved hjelp av parametre. Følgende parametre kan settes i konfigurasjonsfilen:
source_folder_prefix
Oppgi prefix til dataene i produktbøtta som skal prosesseres. Stien oppgis uten bøttenavn. Hvis du setter source_folder_prefix: "forbruk/", betyr det at alle filer under mappen forbruk/ i produktbøtta deles.
Hvis du bare vil dele deler av mappen, kan du bruke underkataloger eller et mer spesifikt prefix. F.eks. vil source_folder_prefix: "forbruk/klargjorte-data/pensjon_p2018" kun prosessere filer i mappen klargjorte-data som starter med pensjon_p2018.
destination_folder
Oppgi mappen i Delomaten-bøtta som Delomaten-jobben skal skrive til. Hvis mappen ikke allerede eksisterer så blir den opprettet i Delomaten-jobben. Mappen skal, i motsetning til source_folder_prefix, oppgis uten /.
En ryddig praksis kan være å bruke samme mappenavn som er oppgitt i source_folder_prefix: "forbruk".
memory_size
Oppgi hvor mye minne prosesseringen av en enkeltfil skal få tilgang til. Spesifisert i Gigabyte. Det er anbefalt å starte med 6 og deretter øke hvis det viser seg at mer er nødvendig.
pseudo
Velges dersom formålet er at Delomaten-jobben skal pseudonymisere data før deling. pseudo-operasjonen støtter ulike metodene som i dapla-toolbelt-pseudo. I eksemplet under vises hvordan man konfigurerer en jobb som skal pseudonymisere kolonnen fnr i alle filer under mappen forbruk i produktbøtta til teamet, og at resultatet skal skrives til delt-bøtta delomatentest i undermappen forbruk.
automation/shared-data/mitt-dapla-team-prod/altinn/config.yaml
Under pseudo har man følgende argumenter:
name
Gi et navn til oppgaven som skal gjøres slik som vist med task_one i eksempelet over. Man kan velge et hvilket som helst man ønsker.
Hvis man skal pseudonymisere alle kolonnene med samme metode og nøkkel så trenger man kun en oppgave. Hvis man f.eks. skal pseudonymisere noen kolonner med with_stable_id, og andre med with_default_encryption, så lager man en oppgave for hver.
columns
Oppgi en kommaseparert liste av kolonner som skal få samme pseudonym.
automation/shared-data/mitt-dapla-team-prod/altinn/config.yaml
shared_bucket: "delomatentest"
source_folder_prefix: "forbruk/"
destination_folder: "forbruk"
memory_size: 6
pseudo:
- name: task_one
columns: [ "fnr", "fornavn" ]
encryption:
method: "with_stable_id"Her pseudonymiseres kolonnen fnrog fornavn med metoden with_stable_id.
automation/shared-data/mitt-dapla-team-prod/ledstill/config.yaml
shared_bucket: "delomatentest"
source_folder_prefix: "forbruk/"
destination_folder: "forbruk"
memory_size: 6
pseudo:
- name: task_one
columns: [ "fnr" ]
encryption:
method: "with_stable_id"
- name: task_two
columns: [ "snr" ]
encryption:
method: "with_papis_compatible_encryption"
- name: task_three
columns: [ "fornavn", "etternavn" ]
encryption:
method: "with_default_encryption"Her pseudonymiseres flere kolonner med forskjellige algoritmer:
fnr-kolonnen pseudonymiseres medwith_stable_id-metoden.snr-kolonnen pseudonymiseres medwith_papis_compatible_encryption-metoden.fornavn- ogetternavn-kolonnene pseudonymiseres medwith_default_encryption-metoden og standard nøkkel.
encryption
Oppgi navnet på krypteringsmetoden som skal benyttes. Metoden angis på samme måte som i dapla-toolbelt-pseudo. Tabell 1 viser hvilke navn som kan velges og hva de betyr.
| Navn | Beskrivelse |
|---|---|
with_stable_id |
Koder om til stabil ID og deretter krypterer med TINK-FPE algoritmen (Papis-algoritmen). |
with_papis_compatible_encryption |
Krypterer direkte med TINK-FPE algoritme (Papis-algoritmen). |
with_default_encryption |
Krypterer med TINK-DAED algoritmen, ofte omtalt som default-algoritmen på Dapla. Standard nøkkel er ssb-common-key-1, men støtter også en annen nøkkel. |
sid_snapshot_date
Angi hvilken versjon av katalog for stabil ID som skal benyttes dersom siste tilgjengelige katalog ikke skal benyttes. Verdien oppgis som en dato på formatet YYYY-MM-DD og pseudonymiseringen bruker da nærmeste tilgjengelige katalog tilbake i tid.
sid_snapshot_date benyttes kun om siste versjon av katalogen ikke skal benyttes, og kan kun benyttes med metoden with_stable_id. Se eksempelkode lenger opp i artikkelen.
automation/shared-data/mitt-dapla-team-prod/altinn/config.yaml
shared_bucket: "delomatentest"
source_folder_prefix: "forbruk/"
destination_folder: "forbruk"
memory_size: 6
pseudo:
- name: task_one
columns: [ "fnr", "fornavn" ]
encryption:
method: "with_stable_id"
sid_snapshot_date: "2024-01-15"Her pseudonymiseres kolonnen fnrog fornavn med metoden with_stable_id og nærmeste SID-katalog (bakover i tid) fra 15. januar 2024 benyttess.
key
Kan angis som et valg man har valgt
method: "with_default_encryption" og ikke ønsker standard-nøkkelen ssb-common-key-1. Siden denne metoden støtter en alternativ nøkkel kan man oppgi key: "ssb-common-key-2" dersom man ønsker det.
De andre metodene støtter kun en nøkkel og man trenger aldri å oppgi key.
automation/shared-data/mitt-dapla-team-prod/altinn/config.yaml
shared_bucket: "delomatentest"
source_folder_prefix: "forbruk/"
destination_folder: "forbruk"
memory_size: 6
pseudo:
- name: task_one
columns: [ "fnr", "fornavn" ]
encryption:
method: "with_default_encryption"
key: "ssb-common-key-2"Her pseudonymiseres kolonnen fnrog fornavn med metoden with_default_encryption og nøkkelen ssb-common-key-2 benyttes.
sid_on_map_failure
Kan angis som et valg hvis
method: "sid_mapping" og man IKKE ønsker at den originale verdien pseudonymiseres direkte dersom den ikke får treff i stabil ID katalogen. Hvis man heller ønsker at pseudonymiseringen returnerer NULL der man ikke får treff. Hvis man ønsker at NULL returneres oppgir man i konfigurasjonsfilen til Delomaten:
sid_on_map_failure: "RETURN_NULL"
automation/shared-data/mitt-dapla-team-prod/altinn/config.yaml
shared_bucket: "delomatentest"
source_folder_prefix: "forbruk/"
destination_folder: "forbruk"
memory_size: 6
pseudo:
- name: task_one
columns: [ "fnr", "fornavn" ]
encryption:
method: "with_stable_id"
key: "ssb-common-key-2"Her pseudonymiseres kolonnen fnrog fornavn med metoden with_stable_id og vi pseudonymiseringen returnerer NULL hvis den ikke fikk treff i SID-katalog.
depseudo
Velges dersom formålet er at Delomaten-jobben skal de-pseudonymisere data før deling. De-pseudonymisering krever at man den opprinnelige pseudonymiseringen er dokumentert i Datadoc og derfor trenger man kun å oppgi hvilke kolonner som skal de-pseudonymiseres.
columns
Oppgi en kommaseparert liste med kolonner som skal de-pseudonymiseres. Se eksempler under.
automation/shared-data/mitt-dapla-team-prod/ledstill/config.yaml
shared_bucket: "delomatentest"
source_folder_prefix: "ledstill/"
destination_folder: "ledstill"
memory_size: 6
depseudo:
columns: ["fnr", "fnr_naa"]Her depseudonymiseres fnr og fnr_naa kolonnene med de samme algoritmene og parameterene som de ble pseudonymisert med.
Denne informasjonen blir hentet fra datadoc metadataen til variablene.
Rulle ut tjenesten
For å rulle ut tjenesten gjør du følgende;
- Push branchen til GitHub og opprette en pull request.
- Pull request må godkjennes av en data-admins på teamet.
- Når pull request er godkjent så sjekker du om alle tester, planer og utrullinger var vellykket, slik som vist i Figur 2.
- Hvis alt er vellykket så kan du merge branchen inn i
main-branchen.
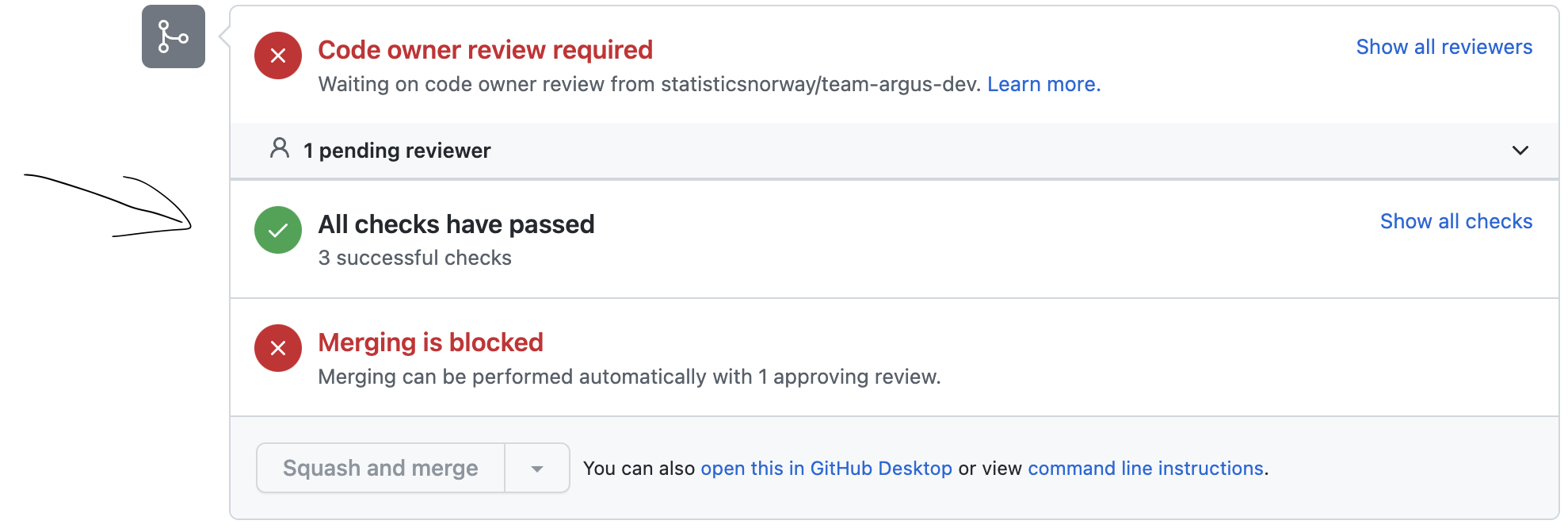
Etter at du har merget inn i main kan du følge med på utrullingen under Actions-fanen i repoet. Når den siste jobben lyser grønt er kildomaten rullet ut og klar til bruk.
Test tjenesten
Siden Delomaten er utformet på den måten at det delende teamet ikke har tilgang til dataene som deles, så må testing koordineres med et av teamene som skal konsumere dataene. Dette kan gjøres på følgende måte:
- Ta kontakt med ett av teamet som skal konsumere dataene som deles med Delomaten.
- Trigg Delomaten manuelt, eller legg en fil på filstien som Delomaten er konfigurert til å prosessere.
- Det delende teamet kan inspisere metadataene som genereres av Delomaten og monitorere logger.
- Diskuter datakvaliteten med det konsumerende teamet.
Når kvaliteten er tilfrestillende kan man dele alle filer som skal deles ved at de flyttes over til den aktuelle mappen. HVis det allerede ligger data der kan man trigge disse manuelt først.
Metadata
Delomaten krever at datasett som deles er dokumentert i Datadoc. Når en fil prosesseres av Delomaten og innholdet i datasettet endres, så oppdaterer Delomaten dokumentasjonen og skriver den sammen med filen til delt-bøtta. Det konsumerende teamet kan derfor være sikre på at dataene fortsatt er riktig dokumentert.
I tillegg til metdata så produseres det metrikker fra prosesseringen som både det delende og det konsumerende teamet får tilgang til. Det konsumerende får tilgang til en fil i delt-bøtta med samme navn som filen som deles, men den har suffix’et __METRICS.json. Denne filen kan f.eks. se slik ut:
{
'fnr': {
'logs': [
'No SID-mapping found for fnr 999999*****',
'No SID-mapping found for fnr XX',
'No SID-mapping found for fnr X8b7k2*'
],
'metrics': [
{'MAPPED_SID': 10},
{'MISSING_SID': 3}
]
}
}Det delende teamet kan få tilgang til denne informasjonen fra loggene til Delomaten-jobben (se neste kapittel).
Monitorering og logging
Når en jobb i Delomaten er satt opp og rullet ut kan tjenesten monitoreres i Google Cloud Console (GCC) ved å gjøre følgende:
- Logg deg inn med SSB-bruker på GCC.
- Velg standardprosjektet i prosjektvelgeren2.
- Søk opp Cloud Run i søkefeltet på toppen av siden og gå inn på siden.
- Velg Worker Pools i menyen til venstre.
På siden til Cloud Run Worker Pools vil du se en oversikt over alle kilder teamet har kjørende i kildomaten. De har formen shared-<kildenavn>-processor. I eksempelet med team dapla-example tidligere, vil man da se en kilde som heter shared-altinn-processor, siden mappen de opprettet under automation/shared-data/dapla-example-prod/ i IaC-repoet heter altinn.
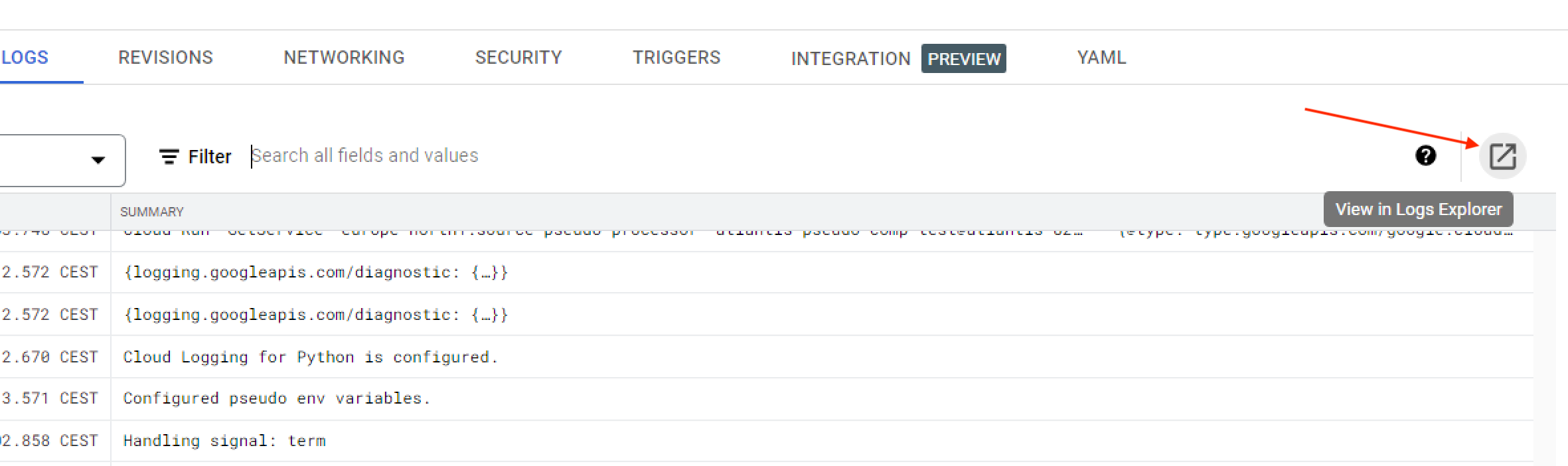
Trykker man seg inn på hver enkelt jobb vil man kunne monitorere aktiviteten i Delomaten, og man kan trykke seg videre for å se loggene.
Det er anbefalt å se på Delomaten-loggene i Logs Explorer. Det kan man enkelt gjøre ved å trykke på “View in Logs Explorer” som vist på bildet under:
Skalering
Delomaten er satt opp for å kunne prosessere hver kilde i opptil 100 parallelle instanser samtidig. Ta kontakt med Kundeservice hvis man opplever problemer med kapasiteten til Delomaten.
Varsling på e-post
Delomaten tilbyr e-postvarsling til teamet når tjenesten feiler. Opprett en Kundeservice-sak for å få satt opp e-postvarsling for teamet ditt.
Varslene sendes kun dersom det oppstår en feilmelding under prosesseringen.
Trigge kilde manuelt
Delomaten er bygget for å trigge på nye filer som oppstår i en gitt filsti. Men noen ganger er det nødvendig å trigge kjøring av filer for en gitt kilde på nytt. Dette kan gjøres med en funksjon i Python-pakken dapla-toolbelt-automation.
Før du kan gjøre dette trenger du følgende informasjon:
- project-id for standardprosjektet. Slik finner du prosjekt-id.
- folder_prefix er mappen i produktbøtta. Man vil da kjøre Delomaten-scriptet for hver fil i denne mappen.
- source_name er navnet på jobben, og vil bestemme hvilket Delomaten-script man bruker for å prosessere filene fra punkt 2. Det vil tilsvare mappenavnene under mappen
automation/shared-data/<team-navn>-prod/i IaC-repoet for teamet.
Hvis man under folder_prefix legger inn en hel filsti med filnavn og filending, så trigges Delomaten kun på denne ene fila.
Her er et kodeeksempel som viser hvordan man kan trigge prossesering av alle filer for jobben altinn:
notebook
from dapla_toolbelt_automation import trigger_shared_data_processing
project_id = "dapla-example-p"
source_name = "altinn"
folder_prefix = "ledstill/altinn/ra0678"
trigger_shared_data_processing(project_id, source_name, folder_prefix)Her er et kodeeksempel som viser hvordan man kan trigge prosessering av spesifike filer i en jobb:
notebook
from dapla_toolbelt_automation import trigger_shared_data_processing
project_id = "dapla-example-p"
source_name = "altinn"
file_paths = [
'ledstill/altin/ra0678/data1.parquet',
'ledstill/altin/ra0678/data2.parquet',
'ledstill/altin/ra0678/data3.parquet'
]
for file in file_paths:
trigger_shared_data_processing(project_id, source_name, file)Tilgangsstyring
Teamet som deler data kan gi tilgang til andre team på lik måte som med standard delt-bøtter. Les mer om tilgangsstyring her.
Vedlikehold
Når tjenesten er rullet ut så vil den kjøre automatisk på alle filer som dukker opp i den oppgitte filstien. Etter hvert vil det være behov for å endre filstier som skal trigge tjenesten, eller prosessere alle filer på nytt. I denne delen forklarer vi hvordan du går frem for å gjøre dette.
Endre config.yaml
Alle på teamet kan gjøre endringer i config.yaml, men det er data-admins som må godkjenne endringene før de blir rullet ut. For å endre config.yaml gjør du følgende:
- Klon repoet.
- Gjør endringene du ønsker i en branch.
- Push opp endringene til GitHub og opprett en pull request.
- Få en data-admins på teamet til å godkjenne endringene.
- Når endringene er godkjent så kan du merge inn i
main-branchen.
En endring i config.yaml krever at tjenesten rulles ut på nytt og tar derfor litt mer tid enn en endring i Python-skriptet.
Metadata
For å hindre dobbeltprosessering og forbedre ytelse bruker Delomaten Cloud Storage sin innebygde metadatafunksjonalitet for å sette noen markører på kildedatafilene. Disse metadatane kan du hente ut f.eks. via dette scriptet:
sjekk-metadata.py
from google.cloud import storage
team = "dapla-example"
env = "prod"
filename = "my-folder/my-file.parquet"
client = storage.Client()
bucket = client.bucket(f"ssb-{team}-data-kilde-{env}")
blob = bucket.get_blob(filename)
print(blob.metadata)Et eksempel på hvordan denne metadataen er som følger:
source-my-source-processor-generation: 2309419879432
source-my-source-processor-status: doneStatus-feltet forteller deg om filen er ferdigprosessert, under arbeid eller om prosesseringen feilet. Verdien for dette feltet vil da være, henholdsvis, done, processing eller failed. Merk at filer som er markert som failed fremdeles kan bli plukket opp igjen, siden Kildomaten vil forsøke å prosessere filen 10 ganger før den gir opp.
Generation-feltet sier akkurat hvilken utgave av filen status-feltet gjelder. Dette feltet er nødvendig ettersom filens metadata ikke blir slettet når en ny utgave blir lastet opp, og Delomaten må holde styr på hva den faktisk har prosessert. Du kan sjekke at dette er den nåværende utgaven av filen ved å sammenligne metadatafeltets verdi med filens generation-felt. Hvis vi utvider eksempelet ovenfor:
sjekk-metadata.py
# ...
metadata_generation = int(blob.metadata["source-my-source-processor-generation"])
print(metadata_generation == blob.generation)Fotnoter
Et Infrastructure-as-Code (IaC)-repo er et GitHub-repo som definerer alle ressursene til teamet på Dapla. Alle Dapla-team har et eget IaC-repo på GiHub med navnet
-iac under statisticsnorway↩︎ Standardprosjektet har navnestrukturen
<teamnavn>-p↩︎