Navnestandard
Data i de permanente datatilstandene inndata, klargjorte data, statistikkdata og utdata skal lagres i Google Cloud Storage (GCS) bøtter og følge en definert navnestandard. Standarden gjelder for både statistikkprodukter og dataprodukter (se forklaringsboks under). Navnestandarden beskrevet i dette kapitlet er derfor gjeldende for alle data som lagres i bøtter i standardprosjektet, som f.eks. produktbøtta og delt-bøttene.
Datatilstanden kildedata omfattes ikke av navnestandarden. Grunnen er at kildedata mottas av SSB i mange former/strukturer og de deles sjelden med andre team. De unike egenskapene til kildedata er også grunnen til at de ikke har samme krav til dokumentasjon i metadatasystemene heller.
Statistikkprodukter er alle produkter som er definert i Statistikkregisteret1. Registeret inneholder alle tidligere og nåværende statstikkprodukter i SSB. Før en statistikk kan publiseres på ssb.no må den være registrert i Statistikkregisteret med informasjon om navn, emneområde, eierseksjon og publiseringstidspunkt. I tillegg får statistikkene tildelt et unikt kortnavn. Eksempler på kortnavn for statistikker er kpi, reise og ftot. Kortnavnet er en viktig del av navnestandarden for datalagring som beskrives i dette kapitlet.
Dataprodukter er bearbeidede data som skal benyttes til andre formål enn direkte publisering på ssb.no. Dataprodukter vil ofte være i disse kategoriene:
- klargjøring av data til forskning og utlån
- bearbeiding av data som skal inngå som en del av andre statistikker
- data som inngår i populasjonsregistre
Det eksisterer ikke et register for dataprodukter, så hvert team må lage et passende kortnavn for hvert produkt. Eksempler på dataprodukt-kortnavn er nudb (utdanningsdatabasen) og fd_trygd (forløpsdatabasen for trygdedata). Kortnavnet til dataprodukter er en viktig del av navnestandarden for datalagring, og skal alltid ha endelsen _data når den lagres i de permanente datatilstandene. F.eks. vil dataproduktet nudb lagres som nudb_data i henhold til navnestandarden.
Mappestruktur
Navnestandarden for lagring av data innfører obligatoriske mapper som alle statistikk- og dataprodukter må følge, samt valgfrie deler hvor teamet selv kan bestemme sin mappestruktur.
Obligatoriske mapper
Ifølge navnestandarden skal følgende mappenivåer alltid eksistere først i en lagringsbøtte:
- Statistikkproduktets eller dataproduktets kortnavn
- Datatilstand
Anta at det er team som heter dapla-example som har produserer statistikkproduktene ledstill og sykefra. I tillegg produserer de et dataprodukt som heter ameld. Deres mappestruktur i produktbøtta vil da se slik ut:
Obligatoriske mapper
ssb-dapla-example-data-produkt-prod/
└─ ledstill/
├── inndata/
├── klargjorte-data/
├── statistikk/
└── utdata/
└─ sykefra/
├── inndata/
├── klargjorte-data/
├── statistikk/
└── utdata/
└─ ameld_data/
├── inndata/
├── klargjorte-data/
├── statistikk/
└── utdata/ Valgfrie mapper
De to første mappenivåene er bestemt og obligatoriske. Teamene kan likevel opprette egendefinerte mapper der det er behov. Det kan gjøres i følgende tilfeller:
- Teamet ønsker å organisere dataene i undermapper for hver datatilstand.
- Teamet trenger å lagre temporære data.
- Det er anbefalt å lage en temp-mappe på første nivå etter bøttenavn, men det er også tillatt å opprette temp-mapper andre steder i mappe-hierarkiet, f.eks.
../inndata/temp/eller../klargjorte-data/temp/.
- Det er anbefalt å lage en temp-mappe på første nivå etter bøttenavn, men det er også tillatt å opprette temp-mapper andre steder i mappe-hierarkiet, f.eks.
- Teamet utfører oppdrag og ønsker et eget sted å lagre data knyttet til dette. Det kan kun gjøres i en oppdrag-mappe på første nivå etter bøttenavn.
Under er et nytt eksempel i produktbøtta for team dapla-example, men nå har de kun statistikkproduktet ledstill, en temp-mappe og en oppdrag-mappe. I tillegg så ønsker de å skille mellom data som er produsert på Dapla og data som er migrert fra tidligere plattform. De gjør det ved å opprette de egendefinerte mappene on-prem og dapla for hver datatilstand.
Obligatoriske og egendefinerte mapper
ssb-dapla-example-data-produkt-prod/
└─ ledstill/
├── inndata/
├── on-prem/
├── dapla/
├── klargjorte-data/
├── on-prem/
├── dapla/
├── statistikk/
├── on-prem/
├── dapla/
└── utdata/
├── on-prem/
├── dapla/
└─ temp/
└─ oppdrag/ Når man oppretter en mappe for oppdrag så er det viktig å kunne knytte dataene til et Websak-saksnummer. Det er derfor anbefalt at det opprettes en undermappe med saksnummeret eller at saksnummeret er med i filnavnet.
Filnavn
Filnavn skal ha en fast struktur som inneholder: en kort beskrivelse, periode, versjon og filtype, slik som vist i Figur 1.
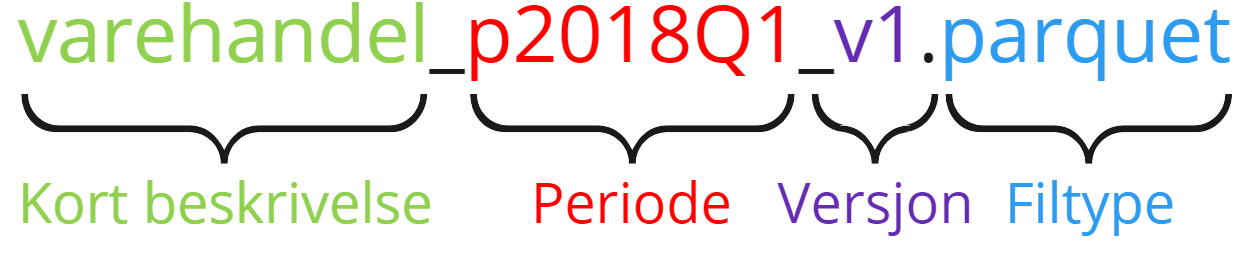
Eksempelet i Figur 1 har varehandel som kort beskrivelse, dataene er gyldige for 2018-Q1, versjon er 1 og filtypen er parquet. I tillegg ser vi at periodeangivelse alltid skal prefixes med p og versjon med v. Elementene i filnavnet skal skilles med understrek.
Det er også verdt å merke seg at mellomrom og særnorske bokstaver som æ, ø og å ikke forekommer i filnavnet. Følgende alfanumeriske tegn kan benyttes i fil- og mappenavn:
- a-z og A-Z2.
- 0-9
- Bruk bindestrek -, eller understrek _, og ikke mellomrom.
Tabell 1 viser en mer inngående beskrivelse av hva som inngår i de ulike delene av et filnavn.
| Element | Forklaring |
|---|---|
| Kort beskrivelse | Kort tekst som forklarer datasettets innhold, f.eks. “varehandel” eller “personinntekt”. Bruk bindestrek hvis beskrivelsen består av flere ord, f.eks. “grensehandel-imputert” eller “framskrevne-befolkningsendringer”. |
| Periode - inneholder data f.o.m. dato | Datasettet inneholder data fra og med dato/tidspunkt. I filnavnet må perioden prefikses med “_p”, eksempel “_p2022” eller “_p2022-01-01”. Se også gyldige formater for periode (dato/tidspunkt) |
| Periode - inneholder data t.o.m. dato | Datasettet inneholder data til og med dato/tidspunkt. Denne brukes ved behov, eksempelvis for datasett som inneholder forløpsdata eller datasett med flere perioder/årganger. |
| Versjon | Versjon av datasettet. I filnavnet må versjonsnummeret prefikses med “_v”, eksempel “v1”, “v2” eller “v3”. |
| Filtype | Filendelse som sier noen om filtypen, f.eks. “.json”, “.csv”, “.xml” eller “.parquet”. |
Partisjonerte data
Team som partisjonerer sine filer ved lagring skal fortsatt følge navnestandarden. Det som endrer seg er at filtype ikke blir en del av filnavnet, men heller kommer inn under partisjoneringen. Anta at team dapla-example partisjonerer et datasett i datatilstand inndata som heter skjema_p2018_p2020_v1. Anta også at de partisjonerer dataene med hensyn på kolonnen aar. Da vil de i henhold til navnestandarden opprette denne strukturen:
Mappestruktur partisjonert data
ssb-dapla-example-data-produkt-prod/
└─ ledstill/
├── inndata/
└── skjema_p2018_p2020_v1
└── aar=2018
└── data.parquet
└── aar=2019
└── data.parquet
└── aar=2020
└── data.parquet
├── klargjorte-data/
├── statistikk/
└── utdata/ Eksempel: Produktbøtte for team dapla-example
Anta at det er team som heter dapla-example med statistikkproduktene ledstill og sykefra, og de har et dataprodukt med kortnavnet ameld. Teamet har følgende mappestruktur i produktbøtta:
Produktbøtta: ledstill, sykefra og ameld
ssb-dapla-example-data-produkt-prod/
└─ ledstill/
├── inndata/
│ ├── skjema_p2024-Q1_v1.parquet
│ ├── skjema_p2024-Q2_v1.parquet
│ └── skjema_p2024-Q2_v2.parquet
├── klargjorte-data/
│ ├── editert_p2024-Q1_v1.parquet
│ └── editert_p2024-Q2_v1.parquet
├── statistikk/
│ ├── aggregert_p2024-Q1_v1.parquet
│ └── aggregert_p2024-Q2_v1.parquet
└── utdata/
│ ├── statbank_p2024-Q1_v1.parquet
│ └── statbank_p2024-Q2_v1.parquet
│
└─ sykefra/
├── inndata/
│ ├── egenmeldt_p2024-Q1_v1.parquet
│ ├── egenmeldt_p2024-Q2_v1.parquet
│ ├── legemeldt_p2024-Q1_v1.parquet
│ └── legemeldt_p2024-Q2_v1.parquet
├── klargjorte-data/
│ ├── sykefravaer_p2024-Q1_v1.parquet
│ └── sykefravaer_p2024-Q2_v1.parquet
├── statistikk/
│ ├── aggregert_p2024-Q1_v1.parquet
│ └── aggregert_p2024-Q2_v1.parquet
└── utdata/
│ ├── statbank_p2024-Q1_v1.parquet
│ └── statbank_p2024-Q2_v1.parquet
│
└─ ameld_data/
├── inndata/
│ ├── ameldingen_p2024-11_v1.parquet
│ └── ameldingen_p2024-12_v1.parquet
└── klargjorte-data/
│ ├── ameldingen_p2024-11_v1.parquet
│ └── ameldingen_p2024-12_v1.parquetVersjonering av datasett
Versjonering er obligatorisk når man jobber med data på dapla. Hovedgrunnen til at vi versjonerer er for å dekke kravet om uforanderlighet og etterprøvbarehet: at data-konsumenter (menneske eller maskin) skal ha kontroll på endringer. Derfor skal et datasett som er brukt i statistikkproduksjon aldri slettes - det skal opprettes en ny versjon av datasettet. Les mer om prinsippet om uforanderlighet av data på confluence-siden til IT-Arkitektur.
Kort fortalt innebærer versjonering av data at datasettene har versjonsnummer før filendelsen. For eksempel: framskrevne-befolkningsendringer_p2019_p2050_v1.parquet
Når man lagrer den obligatoriske versjonerte filen, har man mulighet til å samtidig lagre en uversjonert versjon. Feks. “filnavn_v1.parquet” + “filnavn.parquet”. Dette gjør at konsumenten til en hver tid bruker “nyeste” versjon av fila, og kan derfor forenkle konsumeringen av den uversjonerte filen. Men, det er noen ting man bør være OBS på: 1. Hvordan sikrer man reproduserbarhet, når det ikke logges hos konsumenten hvilken versjon av filen som ble konsumert? 2. Kan du garantere at du alltid skriver over den uversjonerte filen, eller er det en mulighet for at den kan bli “hengende bak” de versjonerte filene? Det anbefales derfor kun å benytte filnavn med versjonsnummer (unngå uversjonerte filer)! Dette vil også forenkle dokumentasjon av datasett i DataDoc, tilgjengeliggjøring i datakatalogen, og er nødvendig for en ryddig deling av data.
Man trenger ikke versjonere temporære data.
Når skal man lagre ny versjon?
Følgende hendelser skaper ny versjon av et datasett:
Reberegninger av data med nye metoder.
Korrigeringer av verdier.
Oservasjoner legges til eller fjernes.
Oppdatert eller erstattet kodeverk.
Variabler fjernes eller legges til.
- Hvis det gjøres vesentlige endringer (mange variabler) så bør det vurderes om dette er et helt nytt datasett.
Andre strukturendringer, f.eks. bytte av datatyper eller formater.
Med andre ord: enhver endring skaper en ny versjon!
Versjonering i praksis
For hver versjon som oppstår av datasettet opprettes det en ny fysisk fil hvor versjonsnummeret økes med en. Alle gamle versjoner av et datasett skal også eksistere i mappen.
Etterhvert som man får flere versjoner av et datasett kan det se slik ut:
Mappe med flere versjoner av et datasett
ssb-prod-team-personstatistikk-data-produkt-prod/
└── befolkningsframskrivinger/
└── klargjorte-data/
├── framskrevne-befolkningsendringer_p2019_p2050.parquet
├── framskrevne-befolkningsendringer_p2019_p2050_v1.parquet
├── framskrevne-befolkningsendringer_p2019_p2050_v2.parquet
└── framskrevne-befolkningsendringer_p2019_p2050_v3.parquetEksempelet over viser at siste versjon av en fil kan lagres med og uten versjonsnummer for å gjøre det lettere å lese inn nyeste versjon.
Eksempelkode med pakken ssb-fagfunksjoner
Python kode fra SSB-fagfunksjoner for finne neste filversjon
# importer funksjonen next_version_path() fra ssb-fagfunksjoner
from fagfunksjoner import next_version_path
filsti = 'gs://ssb-prod-team-personstatistikk-data-produkt-prod/befolkningsframskrivninger/klargjorte-data/framskrevne-befolkningsendringer_p2019_p2050.parquet'
ny_filsti = next_version_path(filsti)
print(ny_filsti)
# vil returnere:
# 'gs://ssb-prod-team-personstatistikk-data-produkt-prod/befolkningsframskrivninger/klargjorte-data/framskrevne-befolkningsendringer_p2019_p2050_v4.parquet'ssb-fagfunksjoner har også følgende funksjoner for å gjøre versjonering lettere:
get_fileversions()# Retrieves a list of file versions matching a specified pattern.latest_version_number()# Function for finding latest version in use for a file.latest_version_path()# Finds the path to the latest version of a specified file.
R-kode fra fellesr for finne neste filversjon
library(fellesr)
fil = "/buckets/produkt/dapla-manual-examples/testdata_p2025-Q2_v1.parquet"
ny_filsti = lag_versjonert_filsti(fil, versjon = "ny")
print(ny_filsti)
# Vil returnere: "/buckets/produkt/dapla-manual-examples/testdata_p2025-Q2_v2.parquet"fellesr har også følgende funksjoner for å gjøre versjonering lettere: * finn_filversjoner(fil) # Skaffer en liste over filversjoner som matcher filnavn (KOMMER). * finn_versjon(lag_versjonert_filsti(fil, versjon = "siste")) # Nøstet funksjon som finner nummeret til en riktig versjonert fil. * lag_versjonert_filsti(fil, versjon = "siste") # Finner stien til den siste versjonen av en spesifisert fil.
Tidligere delte/publiserte data skal ikke slettes eller overskrives!
Det må derfor lagres fysiske filer for hver versjon av datasettet. Dette er viktig for at SSB skal oppfylle krav om etterprøvbarhet av statistikkene.
Versjon 0: Deling av data som ikke har oppnådd stabil tilstand
Hvis det er behov for å dele data som fortsatt er under innsamling eller pågående klargjøring gjøres dette ved å bruke versjonsnummer 0 i filnavnet.
Dette versjonsnummeret skal kun brukes midlertidig fram til datasettet oppnår stabil tilstand. Ved stabil tilstand byttes versjonsnummer for datasettet til 1 eller høyere.
Fotnoter
Les mer om hvordan man henter ut informasjon fra API-et til Statistikkregisteret i denne blogg-artikkelen.↩︎
Det er anbefalt at æ, ø og å erstattes med ae, oe og aa, f.eks. naering, oekonomi eller levekaar.↩︎