Hvordan flytte statistikkproduksjon til Dapla?
I denne artikkelen beskriver vi hva man bør gjøre og hvordan man bør jobbe for å få en statistikk over på Dapla. Rekkefølgen punktene er i er ikke tilfeldig men med unntak av første punkt - planlegging - kan rekkefølgen på hvordan man gjør ting variere.
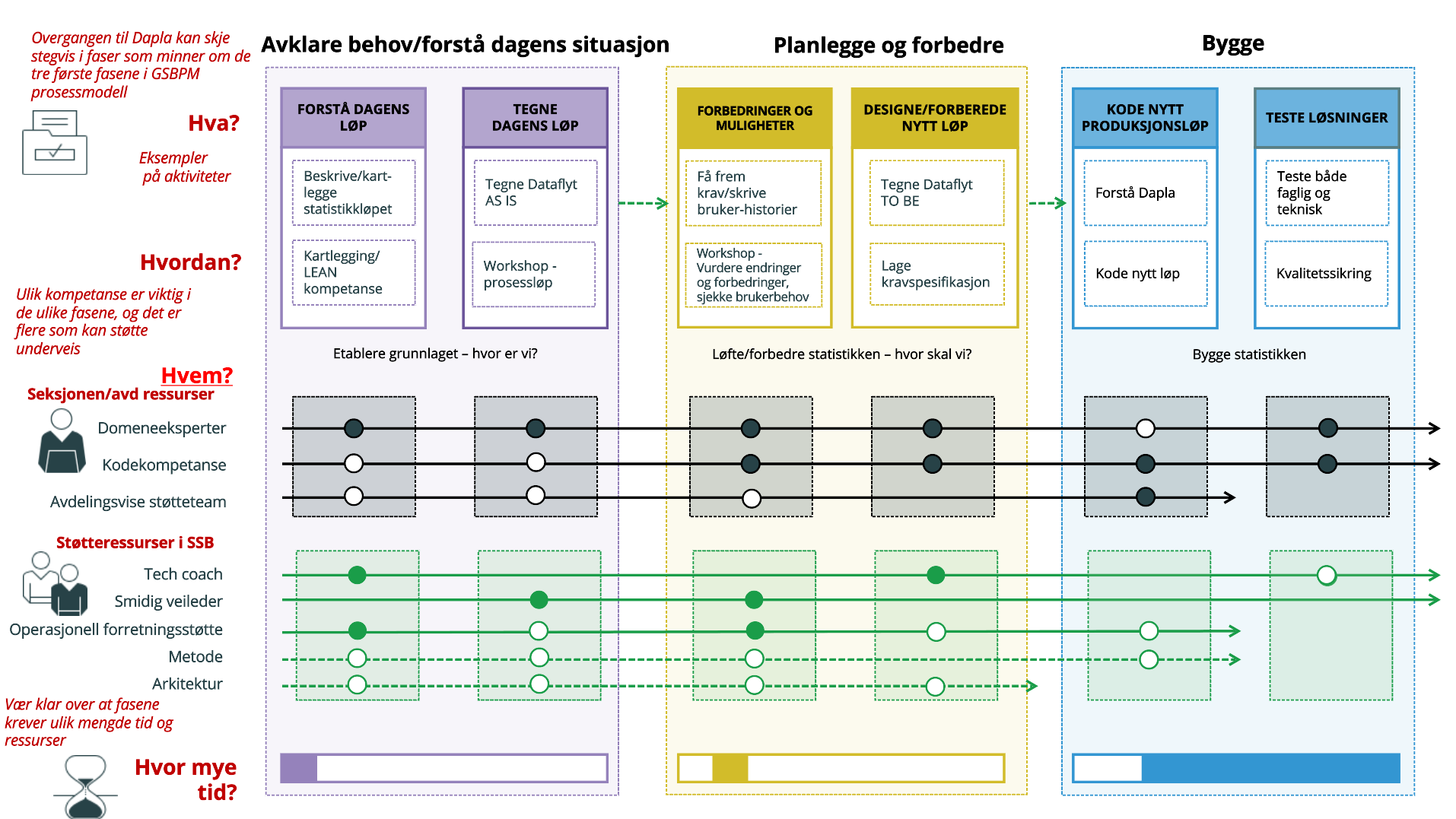
Planlegg overgangen
Når man skal skrive et produksjonsløp på Dapla bør man planlegge godt. En del av dette er å se på dagens systemer for å identifisere forbedringspunkter. Derfor anbefales det at man lager en oversikt over dagens produksjonssystem.
For å forenkle denne prosessen og ha en felles forståelse av både nåværende («as-is») og framtidige («to-be») produksjonsløp, er det laget et helhetlig opplegg som kombinerer et Excel-skjema med automatisk generering av visualiseringer i Tableau.
Kort fortalt innebærer dette at statistikkprodusenter selv fyller inn informasjon om hvilke systemer og datasett som er i bruk, hvordan dataene transformeres underveis, og i hvilken rekkefølge de ulike stegene finner sted. Thomas Bjørnskau kan bistå med dette og konverterer skjemaet til dataflytdiagrammer ved hjelp av Tableau.
I tillegg kan man få veiledning fra Seksjon for Operasjonell forretningsstøtte (s831), støtteteamene og Tech Coachene. Det anbefales det sterkeste å ta kontakt med de nevnte instansene i det man setter i gang med omleggingen av produksjonssystem(ene).
Veien blir til mens man går så det forventes ikke at man har en helhetlig plan for produksjonssløpene før man setter i gang med det konkrete.
Opprett Dapla team
Å bestemme teamstruktur er en naturlig fortsettelse av planleggingen. Her er det først og fremst sikkerhetshensyn som legger føring for hvor mange Dapla team man skal ha per seksjon da Dapla-team er knyttet til tilgansstyring. Et Dapla team skal bestå av medarbeidere som jobber med de samme dataene og statistikkproduktene. Vi anbefaler å ta kontakt med støtteapparatene som ble nevnt i forrige punkt her og.
I applikasjonen Dapla-Ctrl. Dette må gjøres av seksjonsleder. Les brukerveiledning i artikkelen vår om Dapla-Ctrl om du trenger hjelp med det tekniske, men husk å ta den endelige avgjørelsen i samarbeid med støtteapparatene.
Flytt data til Dapla!
En av de viktigste delene av å få en statistikk over på Dapla er å faktisk jobbe på Dapla. Derfor bør man flytte noe data som man kan bruke til å bygge deler av produksjonsløpet. Her kan man enten lage testdata eller bruke fjorårets data. Det anbefales å begynne med inndata da man mest sannsynlig ikke har datafangst på plass når man begynner å legge om et løp.
Når man flytter data bør man begynne å skape seg en oversikt over hvilke data som finnes på bakken og hvordan disse dataene er organisert. Det vil for mange ta lang tid å få oversikt over eksisterende data og hva/hvordan man skal arkivere men det er lurt å begynne å tenke på dette fra første stund.
I tillegg er det viktig at man begynner å tenke på hvordan man skal organisere dataene på Dapla i henhold til navnestandard for datalagring.
Flere i SSB bruker produksjonssonen for å skrive produksjonssløp i Python og R. Det er ikke anbefalt med mindre man har avhengigheter på bakken. Selv om man har avhengigheter på bakken er den generelle anbefalingen at man lager test-data eller flytter inndata fra bakke til sky og utvikler produksjonsløpet fra inndata og ut. Her er noen av grunnene til at vi fraråder å utvikle løpene på bakken:
- Jobber man på bakken isolerer man seg fra ny og viktig Dapla-funksjonalitet.
- Det tar tid å flytte et produksjonsløp fra bakken til sky!
- Jupyter på bakken er ikke skalert for å håndtere produksjonssløp.
Produksjonssonen er likevel et bra sted for å gjøre seg kjent med python og R men så fort man skal faktisk bygge et løp anbefaler vi å gjøre det i skyen.
1. Finn dataene du skal flytte
Bestem deg for hvilke data du skal begynne å jobbe med. Vi anbefaler å begynne med inndata. Kildedata kan overføres når man setter i gang med kildomaten.
3. Flytt dataene til ssb/cloud_sync/<dapla-team>/standard/tilsky/
Flytt så dataene til ssb/cloud_sync/<dapla-team>/standard/tilsky/ på linux. Hvordan dette gjøres spørs på hvor dataene ligger. Ligger dataene på linux kan man enkelt kopiere og lime ved å bruke cp Ligger de på X-disken må man bruke FileZilla. Utvid boksen nedenfor for å lese hvordan man overfører data fra X-disken til linux.
Ligger dataene du vil flytte på X-disken må du bruke FileZilla. Dette er fordi data kun kan synkroniseres mellom linux og google cloud.
For å flytte data fra X-disken følger du denne filsluse-veiledningen skrevet av IT kundeservice.
Det eneste unntaket er at du skal skrive sftp://sl-sas-compute-2 som vert, ikke filsluse.ssb.no
- Dra excel-filen inn i filstrukturen i Jupyterlab
- Kjør følgende kode fra .py-fil i samme område:
import shutil
import os
kilde_fil = 'min_fil_lastet_inn_i_jupyerlab.xlsx'
dest_fil = '/buckets/tilsky/test/min_fil_lastet_inn_i_jupyerlab.xlsx'
folder = os.path.dirname(dest_fil)
os.makedirs(folder, exist_ok=True)
shutil.copy(kilde_fil, dest_fil)- slett excel-filen i Jupyterlab
4: Finn frem til Transfer service-området på Google Cloud Platform
- Gå inn på Google Cloud Console i en nettleser.
- Sjekk, øverst i høyre hjørne, at du er logget inn med din SSB-konto (xxx@ssb.no).
- Velg prosjektet1 som overføringen skal settes opp under.
- Eks. Skal vi overføre inndata for teamet prisstat vi velge prosjektet prisstat-p
- Etter at du har valgt prosjekt kan du søke etter Transfer jobs eller Storage transfer i søkefeltet øverst på siden, og gå inn på siden Transfer jobs
5: Lag en transfer job for flytting fra bakke til sky
- Trykk så på
CREATE TRANSFER JOB-knappen. - Velg POSIX filesystem under source type, og Google Cloud Storage under Destination type
- Velg mellom Batch og Event-driven under Scheduling mode
- Velg transfer_service_default under Agent pool
- Velg skriv tilsky/ under Source directory path
- Velg bøtte du vil overføre til. Enten tilsky (ssb-
-data-tilsky-prod ) eller produkt (ssb--data-produkt-prod ) - Velg overførignshyppighet. Velger du Run once kan du uansett kjøre tjenesten manuelt i fremtiden
- Skriv en kort beskrivelse (eks. ‘Bakke til sky - engangskjøring’)
- Voilà!
6: Kjør transfer job!
Gå tilbake til transfer jobs-siden og kjør din nye transfer-job ved å trykke på jobb-navnet og Start a run
Lag repo med SSB-project
Man bør også lage et repository for statistikken man skal jobbe med tidlig i prosessen. Ifølge navnestandarden skal reponavnet begynne med stat-.
Kort fortalt gjør man det ved å kjøre ssb-project create <repo-navn> --github --github-token='<din token>'. Dette forutsetter at man har konfigurert GitHub-bruker. Les om hvordan man gjør det i vår artikkel om Git og Github.
Les mer i artikkelen vår om SSB-project!
Nysgjerrig på hvordan et SSB-project repo ser ut? Sjekk ut stat-eksempel på GitHub - et fiktivt produksjonsløp utviklet av A200 støtteteam.
Jobb deg gjennom datatilstandene
Når alt annet er på plass kan man begynne å lage det nye produksjonssystemet - en datatilstand om gangen. Det er slik vi har gjort det i stat-eksempel. Vi har et kapittel om standarder med flere nyttige artikler, deriblant artikkelen om datatilstander.
Tips og ting å tenke på
Ta finpussen til slutt!
- Ref. First Rule Of Optimization
- Ikke heng deg opp i finpuss som detaljert dokumentasjon, visualiseringer og nice-to-haves -> God dokumentasjon underveis er viktig, men vi anbefaler å ta detaljene til slutt
Bruk ssb-fagfunksjoner - en python-pakke med masse fellesfunksjonalitet
- … som for eksempel funksjoner for versjonering vist frem i navnestandard-artikkelen vår.
Gjør det godt kjent med krav og standarder
- Investerer man tid i å standardene og kravene til statistikkproduksjon på Dapla i starten av en overgang vil man unngå hodebry i fremtiden og spare mye tid. Les artiklene våre om standarder.
Be om hjelp!
- Bruk støtteteamene, statistikktjenester, viva engage og andre kanaler
Fotnoter
Du kan velge prosjekt øverst på siden, til høyre for teksten Google Cloud. I bildet under ser du at hvordan det ser ut når prosjektet
dapla-felles-per valgt. ↩︎
↩︎