Kildomaten
Kildomaten er en tjeneste for å automatisere deler av overgangen fra kildedata til inndata.
Tjenesten lar statistikkere kjøre sine egne skript automatisk på alle nye filer i kildedatabøtta og skrive resultatet til produktbøtta. Formålet med tjenesten er minimere behovet for tilgang til kildedata samtidig som teamet selv bestemmer hvordan transformasjonn til inndata skal foregå. Statistikkproduksjon kan da starte i en tilstand der dataminimering og pseudonymisering allerede er gjennomført.
Anbefalt prosessering som bør skje i Kildomaten er:
- Dataminimering: Fjerne alle felter som ikke er strengt nødvendig for å produsere statistikk.
- Pseudonymisering: Pseudonymisering av personidentifiserende data.
En forutestning for å bruke kildomaten er å ha et Dapla-team.
Forberedelser
Før et Dapla-team kan ta i bruk kildomaten må tjenesten være aktivert for teamet. Som standard får alle statistikkteam dette skrudd på i prod-miljøet som opprettes for teamet. Ønsker du å aktivere kildomaten i test-miljøet kan dette gjøres selvbetjent som en feature. Alternativt kan man opprette en Kundeservice-sak og be om å hjelp til dette.
Sette opp tjenesten
I denne delen bryter vi ned prosessen med å sette opp kildomaten i de stegene vi mener er hensiktsmessige. Senere i artikkelen forklarer vi hvordan man setter opp flere kilder og hvordan man vedlikeholder tjenesten.
Husk at alle på teamet kan gjøre det meste av arbeidet her, men det er data-admins som må godkjenne at tjenesten rulles ut1.
Klone IaC-repoet
Oppsett av kildomaten gjøres i teamets IaC-repo2. Når vi skal sette opp kildomaten må vi gjøre endringer i teamets IaC-repo. Man finner teamets IaC-repo ved gå inn på SSBs GitHub-organisasjon og søke etter repoet som heter <teamnavn>-iac. Når du har funnet repoet så kan du gjøre følgende:
- Klon teamets IaC-repo
git clone <repo-url> - Bytte mappe til repoet
cd <repo-navn> - Opprett en ny branch:
git switch -c add-kildomaten-source
Mappestruktur i IaC-repo
For at kildomaten skal fungere må det opprettes en bestemt mappestruktur i IaC-repoet til teamet.F.eks. vil mappestrukturen for prod-miljøet se slik ut for team dapla-example:
github.com/statisticsnorway/dapla-example-iac
dapla-example-iac
├── automation/
│ └── source-data/
│ ├── dapla-example-prod/
│ └── README.md
│
│...Skal du sette opp kildomaten i prod-miljøet kan du følge oppskriften som kommer senere i kapitlet uten å gjøre noe mer enda. Vær oppmerksom at mappe navnet til kilden ikke kan være lengere enn 23 tegn. For eksempel vil et mappenavn som frukt_innsamling i stien automation/source-data/data-example-prod/frukt_innsamling være gyldig, men et mappenavn som maanedlig_innsamling_av_frukt_data i stien automation/source-data/data-example-prod/maanedlig_innsamling_av_frukt_data bli for langt.
Skal du også bruke kildomaten i test-miljøet må du opprette en ny mappe og lage en PR i IaC-repoet til teamet. Da vil strukturen se slik ut:
github.com/statisticsnorway/dapla-example-iac
dapla-example-iac
├── automation/
│ └── source-data/
│ ├── dapla-example-prod/
│ │ └── README.md
│ ├── dapla-example-test/
│...I mappestrukturen over har vi klargjort den grunnleggende mappestrukturen for å ta i bruk kildomaten i prod- og test-miljøet. Neste steg blir å legge de ulike kildene som egne mapper under dapla-example-prod og dapla-example-test. Det viser vi i neste avsnitt.
Flere kilder
Kildomaten lar deg prosessere ulike filstier i kildebøtta med ulike python-script. Dette refereres til som at Kildomaten har flere kilder. For å sette opp en kilde må man følge en definert mappestruktur i IaC-repoet der alle kildene ligger rett under <teamnavn>-prod- eller <teamnavn>-test-mappen. Du kan ikke ha undermapper under en kilde. Du velger selv navnet på kildene/mappene i IaC-repoet, og det vil være navnet på kildene i Kildomaten. Senere i kapitlet ser vi at vi må bruke navnet for trigge re-kjøring av kilder.
Under er et eksempel på hvordan det kan se ut for eksempel-teamet dapla-example:
github.com/statisticsnorway/dapla-example-iac
dapla-example-iac
├── automation/
│ └── source-data/
│ ├── dapla-example-prod/
│ │ └── altinn
│ │ └── ameld
│ ├── dapla-example-test/
│ │ └── altinn
│ │ └── ameld
│ │ └── nudb
│...I eksempelet over ser vi at det er mapper i IaC-repoet for kildene altinn og ameld for både test- og prod-miljøet. I tillegg har test-miljøet en mappe for kilden nudb. Hver av disse kildene kan kjøre et eget Pyton-script på alle filer som skrives til en gitt filsti som man definerer selv.
Et team kan sette opp forskjellige skript for forkskjellige kilder men kildomaten tillater bare ett nivå under automation/source-data-<teamnavn>-<miljø>/. Det vil si at du ikke kan ha undermapper under en kilde. Det er også slik at man alltid må opprette en mappe for en kilde, selv om du kun har en kilde. F.eks. kan man ikke droppe mappen altinn i eksempelet over.
Konfigurasjon og skript
Når mappestrukturen er opprettet kan man legge til konfigurasjonsfilen som beskriver hvilke filer som skal prosesseres, og python-skriptet med koden som skal prosessere filene. Det er to filer for hver datakilde:
- En konfigurasjonsfil
- Et Python-skript
Her ser du hvordan IaC-repoet ser ut med én kilde (altinn):
github.com/statisticsnorway/dapla-example-iac
dapla-example-iac
├── automation/
│ └── source-data/
│ ├── dapla-example-prod/
│ └── altinn/
│ ├── config.yaml
│ └── process_source_data.py
│...Konfigurasjonsfil
Kildomaten trigges ved at det oppstår nye filer i kildebøtta til teamet. Hvorvidt den skal trigges på alle filer, eller kun filer i en gitt undermappe, bestemmer brukeren ved å konfigurere tjenesten i config.yaml. Her kan du også angi hvor mye ressurser prosesseringen skal få.
Hvis vi fortsetter eksempelet vårt fra tidligere med dapla-example kan vi tenke oss at teamet ønsker at kildomaten skal trigges på alle filer som oppstår i kildebøtta under filstien: ssb-dapla-example-data-kilde-prod/altinn/.
For å konfigurere tjenesten i kildomaten må vi legge til en fil som heter config.yaml under automation/source-data/dapla-example-prod/altinn/ slik som vist tidligere. I dette tilfellet vil den ha innholdet som vist til venstre under:
config.yaml
folder_prefix: altinn
memory_size: 1 # GiBssb-dapla-example-data-kilde-prod/
├── altinn/
...Mappestrukturen i kildebøtta er illustrert til høyre, mens config.yaml-fila til venstre viser hvordan vi angir at kildomaten kun skal trigges på nye filer som oppstår i undermappen ssb-dapla-example-data-kilde-prod/altinn/. Vi bruker nøkkelen folder_prefix for å angi hvilken sti i kildebøtta som tjenesten skal trigges på. Nøkkelen memory_size lar brukeren angi hvor mye minne og CPU hver prosessering skal få. Vil du at alle filer skal trigge kildomaten? Da setter du folder_prefix til "".
Som standard får hver prosessering med kildomaten 1 CPU-kjerne og 512MB minne/RAM. Hvis man skal gjøre mye prossesering, eller filene som prosesseres er veldig store, kan man sette memory_size opp til max 32GB minne. Antall CPU-kjerner blir satt implisitt ut i fra valg av memory_size iht til begrensningene som Google setter for Cloud Run. Se de nøyaktige verdiene som blir satt her.
Python-skript
- Skriptet ditt kommer til å bli kjørt på en-og-en fil.
- Skriptet ditt må skrive ut et unikt navn på filen som skal skrives til produktbøtta, ellers risikerer du at filer blir overskrevet.
- Python-pakkene som kan benyttes er definert her. Ved behov for andre pakker, ta kontakt med Kundeservice.
- Bøttemontering gjelder ikke for kildomaten, så man må bruke pakken
gcsfsnår man gjør filoperasjoner i kildomaten.
Python-skriptet er der teamet angir hva slags kode som skal kjøre på hver fil som dukker opp i den angitte mappen i kildebøtta. For at dette skal være mulig må koden følge disse reglene:
- Koden må ligge i en fil som heter
process_source_data.py. - Koden må pakkes inn i en funksjon som heter
main().
sys.exit eller lignende
Skriptet ditt kjøres som en del av et større program, og bruk av exit-funksjoner vil hindre resten av Kildomaten i å virke som den skal og kan forårsake uprosesserte filer og uendelige omstarter. Hvis du har brukt sys.exit i skriptet ditt, vil dette oppdages i pull request-en og du vil bli hindret fra å rulle ut koden.
Hvis du vil stoppe prosesseringen pga. en feil bør du bruke exceptions. Kildomaten forstår da at noe har gått galt i prosesseringen og vil i tillegg varsle teamet på e-post dersom dette har blitt konfigurert.
main() er en funksjon med ett parameter som heter source_file som du alltid får av kildomaten når en fil blir prosessert. Når man skriver koden kan man derfor anta at dette parameteret blir gitt til funksjonen, og du kan benytte det inne i main-funksjonen.
source_file-parameteret gir main() en ferdig definert filsti til filen som skal prosesseres. For eksempel kan source_file ha verdien gs://ssb-dapla-example-data-kilde-prod/altinn/test20231010.csv hvis filen test20231010.csv dukker opp i ssb-dapla-example-data-kilde-prod/altinn/.
Hvis vi fortsetter eksempelet fra tidligere ser mappen i IaC-repoet vårt slik ut nå:
github.com/statisticsnorway/dapla-example-iac
├── automation/
│ └── source-data/
│ ├── dapla-example-prod/
│ └── altinn/
│ ├── config.yaml
│ └── process_source_data.py
│
│...Vi ser nå at filene config.yaml og process_source_data.py ligger i mappen automation/source-data/dapla-example-prod/altinn/. Senere, når vi har rullet ut tjenesten, vil en ny fil i gs://ssb-dapla-exmaple-data-kilde-prod/altinn/ trigge kildomaten og kjøre koden i process_source_data.py på filen.
Under ser du et eksempel på hvordan en vanlig kodesnutt kan konverteres til å kjøre i kildomaten:
Vanlig kode
import pandas as pd
# Stien til filen
source_file = "gs://ssb-dapla-example-data-kilde-prod/altinn/test20231010.csv"
df = pd.read_csv(source_file)
# Dataminimerer ved å velge kolonner
df2 = df[['col1', 'col2', 'col3']]
# Skriver ut fil til produktbøtta
df2.to_parquet("gs://ssb-dapla-example-data-produkt-prod/test20231010.parquet")Kode i Kildomaten
import pandas as pd
def main(source_file):
df = pd.read_csv(source_file)
# Dataminimerer ved å velge kolonner
df2 = df[['col1', 'col2', 'col3']]
# Bytter ut "kilde" med "produkt" i filstien
new_path = source_file.replace("kilde", "produkt")
# Bytter ut ".csv" med ".parquet" i filstien
new_path2 = new_path.replace(".csv", ".parquet")
# Skriver ut fil til produktbøtta
df2.to_parquet(new_path2)De to kodesnuttene over gir det samme resultatet, bare at koden til venstre kjøres som vanlig python-kode, mens koden til høyre kjøres i kildomaten. Som vi ser av koden til høyre så trenger vi aldri å hardkode inn filstier i Kildomaten. Tjenesten gir oss filstien, og vi kan bruke den til å skrive ut filen til produktbøtta.
Strukturen på filene som skrives bør tenkes nøye gjennom når man automatiseres prosessering av data. Hvis vi ikke har unike filnavn eller stier kan du risikere at filer blir overskrevet. Typisk er dette allerede tenkt på når filer skrives til kildebøtta, så hvis man kopierer den strukturen, slik vi gjorde i eksempelet over, så vil det ikke være noe problem.
Test koden
Før man ruller ut koden i tjenesten er det greit å teste at alt fungerer som det skal i Dapla Lab. Hvis vi tar utgangspunkt i eksempelet over kan vi teste koden ved å kjøre følgende nederst i skriptet i en data-admins-tjeneste:
process_source_data.py
main("gs://ssb-dapla-example-data-kilde-prod/altinn/test20231010.csv")Merk at siden man i en data-admins-tjeneste kun har tilgang til kildebøtta, og ikke produktbøtta, så vil kjøringen feile når den prøver å skrive resultatet til en fil i produktbøtta.
Når tjenesten er rullet ut vil det være dette som kjøres når en fil dukker opp i gs://ssb-dapla-example-data-kilde-prod/altinn/. Ved å kjøre det manuelt på denne måten får vi sett at ting fungerer som det skal.
Husk å fjerne kjøringen av koden før du ruller ut tjenesten.
Du kan teste kode fra Jupyter og andre IDE-er i prod-miljøet på Dapla med mindre prosesseringen innebærer bruk av pseudonymisering. Grunnen til dette er at det ikke er ønskelig å gjøre det lett å se upseudonymisert og pseudonymisert data samtidig. Hvis man ønsker å teste prosesseringen av pseudo-tjenesten kan man gjøre med testdata i test-miljøet.
Rull ut tjenesten
For å rulle ut tjenesten gjør du følgende;
- Push branchen til GitHub og opprette en pull request. Se hvordan på punktet 4 her.
- Pull request må godkjennes av en data-admins på teamet.
- Når pull request er godkjent så sjekker du om alle tester, planer og utrullinger var vellykket, slik som vist i Figur 1.
- Hvis alt er vellykket så kan du merge branchen inn i
main-branchen.
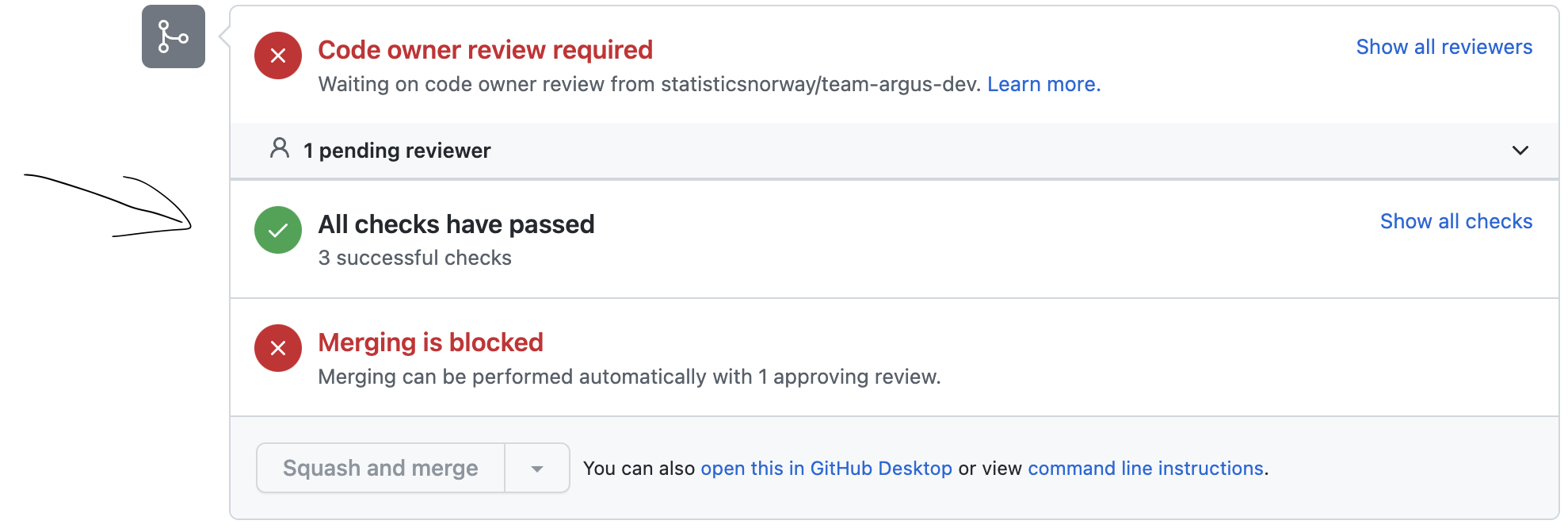
Etter at du har merget inn i main kan du følge med på utrullingen under Actions-fanen i repoet. Når den siste jobben lyser grønt er kildomaten rullet ut og klar til bruk.
For å gi raskt tilbakemelding på noen mulige feilsituasjoner kjøres det enkel validering på config.yaml og process_source_data.py når en Pull request er opprettet. Følgende validering gjennomføres:
- Heter python-skriptet
process_source_data.py? - Finnes en
config.yamlmed gyldigfolder_prefix:? - Bruker
process_source_data.pybiblioteker som ikke er installert i kildomaten? - Har koden i
process_source_data.pyfeil iht. Pyflakes? - Bruker du
sys.exiti koden?
Det kan også forekomme at Atlantis, verktøyet for å rulle ut endringer fra IaC-repoet til GCP, feiler. Da kan du prøve å skrive atlantis plan i kommentarfeltet til pull request-en, og testene vil kjøre på nytt. Hvis det fortsatt ikke fungerer kontakter man Dapla kundeservice.
Test tjenesten
Når du har rullet ut tjenesten kan du teste tjenesten ved at data-admins flytter en fil til den filstien kildomaten er satt opp for. I eksempelet vi har brukt tidligere, gjør du følgende: 1. Åpne en tjeneste i Dapla Lab med teamets data-admins-gruppe valgt i Data-menyen. 2. Kopier en fil over til filstien: gs://ssb-dapla-example-data-kilde-prod/altinn/ 3. Sjekk om filen ble skrevet til ønsket mappe i produktbøtta.
Du kan også sjekke logger og monitorere kildomaten.
Monitorering og logging
Når en kilde i kildomaten er satt opp og ruller ut kan tjenesten monitoreres i Google Cloud Console (GCC) ved å gjøre følgende:
- Logg deg inn med SSB-bruker på GCC.
- Velg standardprosjektet i prosjektvelgeren3.
- Søk opp Cloud Run i søkefeltet på toppen av siden og gå inn på siden.
- Velg Worker Pools i menyen til venstre.
På siden til Cloud Run Worker Pools vil du se en oversikt over alle kilder teamet har kjørende i kildomaten. De har formen source-<kildenavn>-processor. I eksempelet med team dapla-example tidligere, vil man da se en kilde som heter source-altinn-processor, siden mappen de opprettet under automation/source-data/dapla-example-prod/ i IaC-repoet heter altinn.
Trykker man seg inn på hver enkelt kilde vil man kunne monitorere aktiviteten i kilden, og man kan trykke seg videre for å se loggene.
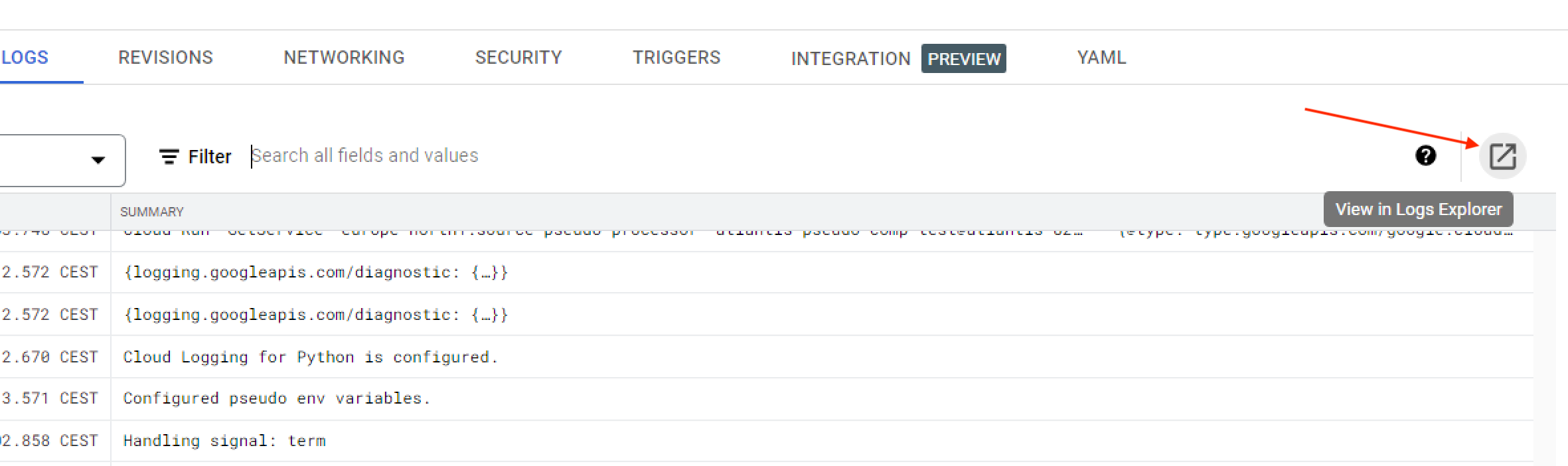
Det er anbefalt å se på Kildomaten-loggene i Logs Explorer. Det kan man enkelt gjøre ved å trykke på “View in Logs Explorer” som vist på bildet under:
Sjekk prosesseringsstatus
Kildomaten lar deg sjekke om filprosessering har feilet, blitt vellykket eller forstatt pågår. Kodeeksempelet fordrer at man har installert python-pakken google-cloud-storage.
sjekk-status-kildomaten.py
from google.cloud import storage
team = "prisstat" # skriv inn teamnavn
env = "prod"
status = "failed" # let etter filer som har failed status. evt. done/processing for andre resultater
source_name = "ra2900" # refererer til denne mappen: https://github.com/statisticsnorway/prisstat-iac/tree/main/automation/source-data/prisstat-prod/ra2900
source_name = source_name.lower().replace("_", "-")
prefix = "ra2900"
client = storage.Client()
bucket = client.bucket(f"ssb-{team}-data-kilde-{env}")
results = []
for blob in bucket.list_blobs(prefix=prefix):
if blob.metadata.get(f"source-{source_name}-status", "") == status:
results.append(blob.name)
print(results) # skriver ut filnavn for filer hvor prosessering feiletSkalering
Kildomaten er satt opp for å kunne prosessere hver kilde i opptil 100 parallelle instanser samtidig. Ta kontakt med Kundeservice hvis man opplever problemer med kapasiteten til Kildomaten.
Varsling på e-post
Kildomaten tilbyr e-postvarsling til teamet når tjenesten feiler. Opprett en Kundeservice-sak for å få satt opp e-postvarsling for teamet ditt.
Varslene sendes dersom det oppstår en feilmelding under prosesseringen. Det betyr at dersom du vil trigge et varsel fra koden din, så har du to muligheter:
varsling.py
# 1. Bruk en exception.
# I dette tilfellet vil prosesseringen stanse og filen markeres som feilet.
def main(source_file):
raise Exception("Kunne ikke prosessere fil pga..")
# 2. Log en feilmelding manuelt
# I dette tilfellet vil ikke prosesseringen stanse. Hvis ingen flere feil (exceptions) skjer,
# så markeres filen som prosessert.
import logging
def main(source_file):
logging.error("Ikke-kritisk feil")Som det er hintet til i koden så anbefales alternativ 1 for uhåndterbare feil hvor prosesseringen ikke kan fortsette, mens alternativ 2 passer bra for feil som ikke hindrer prosessering, men som man vil bli varlset om allikevel.
Flere kilder
Man kan sette opp så mange kilder man ønsker. Men når man setter det opp er det viktig å huske at alle kildene må spesifiseres rett under automation/source-data/<teamnavn>-<miljø>/. Her er et eksempel på hvordan team dapla-example har to kilder i kildomaten:
github.com/statisticsnorway/dapla-example-iac
dapla-example-iac
├── automation/
│ └── source-data/
│ ├── dapla-example-prod/
│ └── altinn/
│ ├── config.yaml
│ └── process_source_data.py
│ └── ledstill/
│ ├── config.yaml
│ └── process_source_data.py
│...I eksempelet over ser vi det er to kilder: altinn og ledstill. Hver kilde trigges på ulike filstier i kildebøtta, og python-koden som kjøres kan være ulik mellom kilder.
Test-miljø
I eksempelet som er brukt i denne artiklen er kildomaten satt opp i prodmiljøet til teamet. Man bør egentlig teste ut nye kilder i teamets test-miljø. Kildomaten er ikke satt opp i test-miljøet som standard, og derfor må det skrus på før man kan anvende det. Teamet kan gjøre det selv ved å følge denne beskrivelsen eller ta kontakt med kundeservice og få hjelp til dette.
En av de store fordelene med å sette opp kildomaten-kilder i test-miljøet før man gjør det i prod-miljøet er at tilgang til funksjonalitet i tjenester som pseudo-tjenesten er bredere. Det gjør det lettere for alle i teamet å utvikle koden som skal benyttes.
Når man skal sette opp kildomaten i test-miljøet følger det samme oppskrift som vi har vist for prod-miljøet over. Den store forskjellen er at test-kilder skal legges under en egen mappe under automation/source-data/ i teamets IaC-repo. Eksempelet under med team dapla-example viser hvordan man kan sette opp kildene altinn og ledstill for både prod- og test-testmiljøet:
dapla-example-iac
├── automation/
│ └── source-data/
│ ├── dapla-example-prod/
│ │ ├── altinn/
│ │ │ ├── config.yaml
│ │ │ └── process_source_data.py
│ │ └── ledstill/
│ │ ├── config.yaml
│ │ └── process_source_data.py
│ ├── dapla-example-test/
│ ├── altinn/
│ │ ├── config.yaml
│ │ └── process_source_data.py
│ └── ledstill/
│ ├── config.yaml
│ └── process_source_data.py
│...Som vi ser av mappestrukturen over er det to mapper under automation/source-data:
- dapla-example-prod
- dapla-example-test
Disse to mappene angir om det er henholdsvis prod- eller test-miljøet vi setter opp kilder for.
Trigge kilde manuelt
Kildomaten er bygget for å trigge på nye filer som oppstår i en gitt filsti. Men noen ganger er det nødvendig å trigge kjøring av filer for en gitt kilde på nytt. Dette kan gjøres med en funksjon i Python-pakken dapla-toolbelt-automation.
Trigging av kilder manuelt kan kun gjøres av data-admins på Dapla Lab. På Dapla Lab må man representere en av gruppene når man logger seg inn. Man må også klone og jobbe fra et annet repo enn det IaC repoet, dersom det er nødvendig å kunne hente inn pakker.
Før du kan gjøre dette trenger du følgende informasjon:
- project-id for standardprosjektet. Slik finner du prosjekt-id. Merk at dette ikke er kilde-prosjektet!
- folder_prefix er mappen i kilde-bøtten, det vil si, mappen akkurat under
<dapla-example-prod>. Man vil da kjøre Kildomaten-scriptet for hver fil i denne mappen. - source_name er navnet på kilden, og vil bestemme hvilket Kildomat-script man bruker for å prosessere filene fra punkt 2. Det vil tilsvare mappenavnene under mappen
automation/source-data/<team-navn>-prod/i IaC-repoet for teamet. I eksempelet over ( Oppføring 1) har vi to kilder -altinnogledstill.
Hvis man under folder_prefix legger inn en hel filsti med filnavn og filending, så trigges Kildomaten kun på denne ene fila.
Her er et kodeeksempel som viser hvordan man kan trigge prossesering av alle filer for kilden altinn:
notebook
from dapla_toolbelt_automation import trigger_source_data_processing
project_id = "dapla-example-p"
source_name = "altinn"
folder_prefix = "altinn/ra0678"
trigger_source_data_processing(project_id, source_name, folder_prefix)I eksempelet over trigger vi scriptet som er satt opp for kilden altinn til å kjøre på alle undermapper av ssb-dapla-example-data-kilde-prod/altinn/ra0678/.
Her er et kodeeksempel som viser hvordan man kan trigge prosessering av spesifike filer i en kilde
notebook
from dapla_toolbelt_automation import trigger_source_data_processing
project_id = "dapla-example-p"
source_name = "altinn"
file_paths = [
'altin/ra0678/data1.parquet',
'altin/ra0678/data2.parquet',
'altin/ra0678/data3.parquet'
]
for file in file_paths:
trigger_source_data_processing(project_id, source_name, file)I eksempelet over trigger vi scriptet som er satt opp for kilden altinn til å kjøre på de tre spesifike filene ssb-dapla-example-data-kilde-prod/altinn/ra0678/data1.parquet, ssb-dapla-example-data-kilde-prod/altinn/ra0678/data2.parquet og ssb-dapla-example-data-kilde-prod/altinn/ra0678/data3.parquet.
Vedlikehold
Når tjenesten er rullet ut så vil den kjøre automatisk på alle filer som dukker opp i filsti i kildebøtta. Etter hvert vil det være behov for å endre på skript, endre filstier som skal trigge tjenesten, eller prosessere alle filer på nytt. I denne delen forklarer vi hvordan du går frem for å gjøre dette.
Endre skript
Alle på team kan endre på skriptet, men det er data-admins som må godkjenne endringene før de blir rullet ut. For å endre skriptet gjør du følgende:
- Klon repoet.
- Gjør endringene du ønsker i en branch.
- Push opp endringene til GitHub og opprett en pull request.
- Få en data-admins på teamet til å godkjenne endringene.
- Når endringene er godkjent så kan du merge inn i
main-branchen.
En endring i Python-skriptet krever ikke at tjenesten rulles ut på nytt. Derfor er det ikke like mange tester og kjøringer som gjøres som når man oppretter en helt ny kilde.
Endre config.yaml
Alle på teamet kan gjøre endringer i config.yaml, men det er data-admins som må godkjenne endringene før de blir rullet ut. For å endre config.yaml gjør du følgende:
- Klon repoet.
- Gjør endringene du ønsker i en branch.
- Push opp endringene til GitHub og opprett en pull request.
- Få en data-admins på teamet til å godkjenne endringene.
- Når endringene er godkjent så kan du merge inn i
main-branchen.
En endring i config.yaml krever at tjenesten rulles ut på nytt og tar derfor litt mer tid enn en endring i Python-skriptet.
Metadata
For å hindre dobbeltprosessering og forbedre ytelse bruker Kildomaten Cloud Storage sin innebygde metadatafunksjonalitet for å sette noen markører på kildedatafilene. Disse metadatane kan du hente ut f.eks. via dette scriptet:
sjekk-metadata.py
from google.cloud import storage
team = "dapla-example"
env = "prod"
filename = "my-folder/my-file.parquet"
client = storage.Client()
bucket = client.bucket(f"ssb-{team}-data-kilde-{env}")
blob = bucket.get_blob(filename)
print(blob.metadata)Et eksempel på hvordan denne metadataen er som følger:
source-my-source-processor-generation: 2309419879432
source-my-source-processor-status: doneStatus-feltet forteller deg om filen er ferdigprosessert, under arbeid eller om prosesseringen feilet. Verdien for dette feltet vil da være, henholdsvis, done, processing eller failed. Merk at filer som er markert som failed fremdeles kan bli plukket opp igjen, siden Kildomaten vil forsøke å prosessere filen 10 ganger før den gir opp.
Generation-feltet sier akkurat hvilken utgave av filen status-feltet gjelder. Dette feltet er nødvendig ettersom filens metadata ikke blir slettet når en ny utgave blir lastet opp, og Kildomaten må holde styr på hva den faktisk har prosessert. Du kan sjekke at dette er den nåværende utgaven av filen ved å sammenligne metadatafeltets verdi med filens generation-felt. Hvis vi utvider eksempelet ovenfor:
sjekk-metadata.py
# ...
metadata_generation = int(blob.metadata["source-my-source-processor-generation"])
print(metadata_generation == blob.generation)Pakker og oppdateringer
Det finnes et fast sett med pakker som er tilgjengelig i Kildomaten. Disse pakkene kan sees under [tool.poetry.dependencies]-blokken her.
Dette repoet oppfører seg som et vanlig Poetry-prosjekt, og blir brukt som grunnlaget for alle Kildomaten-jobber.
Eksisterende Kildomaten-jobber blir oppdatert til den nyeste versjonen av dette prosjektet hvis:
- Man gjør endringer i en kilde i et IAC-repo (f.eks. filen (
process_source_data.py)) - Plattformutviklere ruller ut endringer som treffer alle Kildomater. Dette skjer typisk ved:
- Mindre pakkeoppdateringer som ikke har innvirkninger på scriptet.
- Viktige pakkeoppdateringer som fikser produksjonskritiske feil
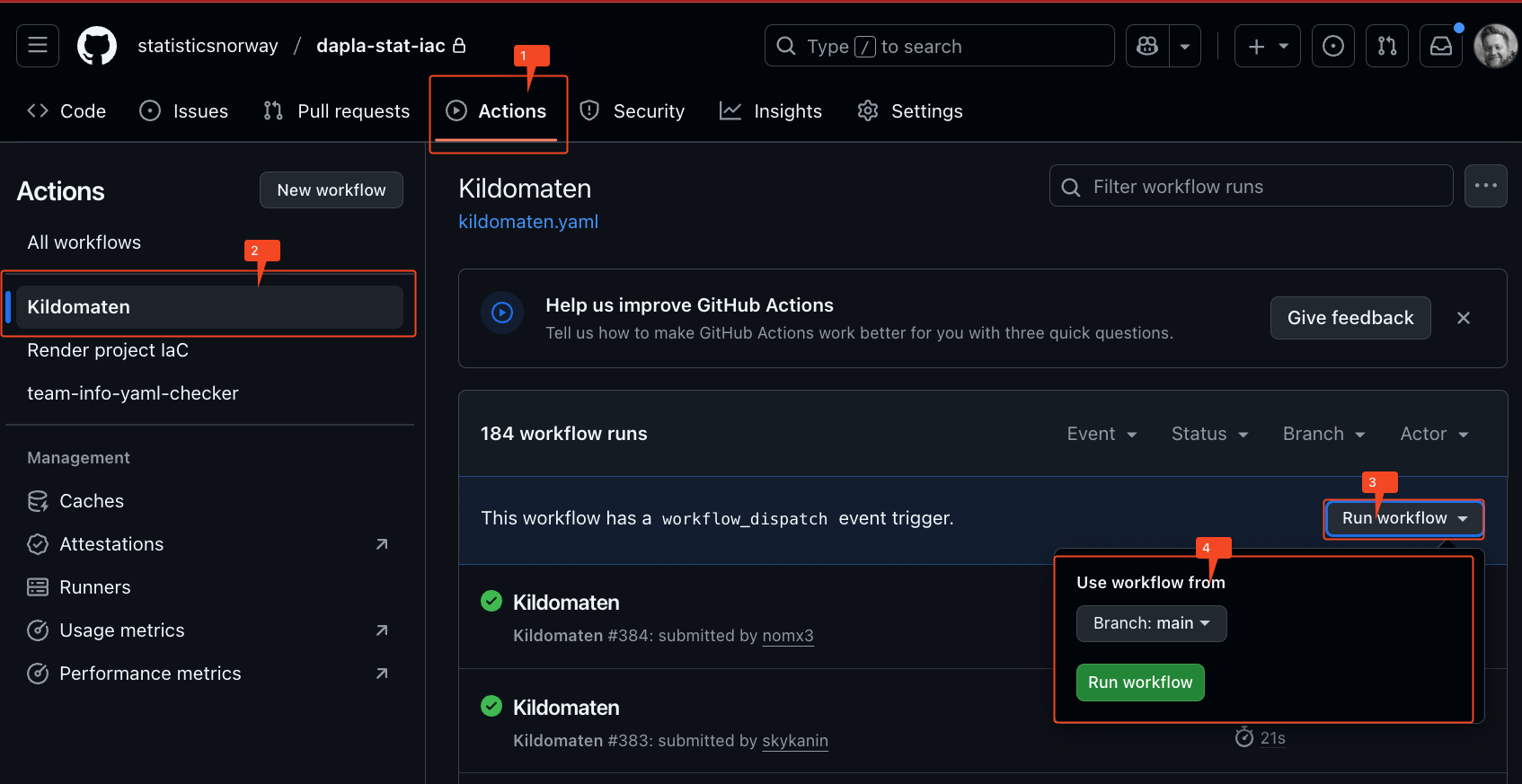
- Man kjører en manuell oppdatering av Kildomaten (se bilde under)
Manuell oppdatering av Kildomaten
Trykk på Actions-fanen i et IAC-repo for teamet med en Kildomat
Velg Kildomaten på venstre side
Utvid Run workflow-menyen
Trykk på den grønne Run workflow-knappen.
Etter noen minutter vil da Kildomaten være oppdatert.
Fotnoter
I tillegg er det data-admins som må teste tjenesten manuelt hvis det gjøres på skarpe data, siden det kun er data-admins som kan få tilgang til de dataene.↩︎
Et Infrastructure-as-Code (IaC)-repo er et GitHub-repo som definerer alle ressursene til teamet på Dapla. Alle Dapla-team har et eget IaC-repo på GiHub med navnet
-iac under statisticsnorway↩︎ Standardprosjektet har navnestrukturen
<teamnavn>-p↩︎